主题
大模型文档
本文用于整理、总结、探索大模型相关技术问题,增强对大模型的理解。会添加八股问题,但希望可以通过知识理解回答,而不是死记硬背。
本文只用来内部分享,所以相对不是很精简,希望通过详细描述达到更深理解。
PreTrain预训练
本章会从Transformer结构开始记录,再到当今主流decoder-only模型,最后说明训练过程中模型在显卡中的变化。
Transformer结构
主要介绍一段input,即一个batch下几个sequence在进入Transformer前、中、后的变化,大致经过为”tokenization→embedding→position encoding→transformer→output(logits)”。
Tokenizer
Tokenizer的主要作用是词句拆分为大模型可以查询的整数数字id,作为Transformer的输入。
例如“珠穆朗玛峰是世界上最高的山峰”,经过https://platform.openai.com/tokenizer后,变为:

而Tokenizer本身存在三个颗粒度,不同的颗粒度会面对不同的问题,如:1.语义信息量确实;2.词表大小;3.Out of Vocabulary。
Word-based Tokenizer 单词级,存在13问题
Character-based Tokenizer 字符级,存在12问题
Subword-based Tokenizer 子词级,兼容123问题
todo:补充tokenizer算法,如有必要
Embedding
Embedding的作用是将token转换为向量,可以理解为一个字典,词句经过tokenizer之后变为数字id,可以在字典中查询自己的向量。字典大小**(vocab_size, d_model)**,其中vocab_size是token词表的大小,来源于Tokenzer算法;d_model是大模型支持的向量维度大小,越大往往对一个token的描述越丰富。
在同一个向量空间中,语义上越相似,空间上越接近。这是大模型所希望的,所以在decoder-only大模型中,Embedding层作为一个可以学习的层,在训练过程,也可以随着反向传播更新参数,让语义上相似的token所表示的向量逐渐接近。
权重绑定:之前decoder-only模型通常将Embedding层和输出层的lm_head共享权重,vocab_size * d_model的参数量庞大,共享参数可以减少参数量。现在通常也有将它们分离的做法。
对于embedding,也有其他算法,比如word2vec,bert等不做过多赘述。
位置编码 Position encode
位置编码的必要性
token经过embedding后需要添加位置信息,因为注意力机制的本质是加权求和,同一组token(例如“我喜欢苹果”)不同顺序得到的结果是相同的,无法区分先后顺序,而在embedding阶段引入位置编码,可以在后续注意力机制中区分顺序,进而理解文本。
位置编码方式主要分为绝对位置编码和相对位置编码。
绝对位置编码主要是三角函数,上下文长度有限,无法进行有效外推。
相对位置编码中主流是RoPE,旋转位置编码,通过线性代数,对一些向量注入位置信息。
旋转位置编码RoPE
要求长度必须为偶数,将向量中的每一对相邻维度作为二维坐标,施加一个基于向量的旋转角度。
然后对每一对进行旋转
其中角度是与token的位置相关:
相对位置编码具有平移不变性的特点,1、2和101、102在相对位置上是一致的,词与词之间的依赖关系也是一致的。
RoPE旋转位置编码,是将位置信息注入到Q、K中,且具有远程衰减性(两个词离得越远,旋转后内积贡献越小),而不是像绝对位置编码在embedding层处理。同时V保持不变,因为位置信息只影响“谁和谁相关”(QK的内积),而不需要影响“提取什么信息”(V的内容)
Attention注意力机制
前三个小节已经处理好了token,现在需要Transformer对他们处理,本节主要介绍Transformer的核心,注意力机制,了解相关公式后再观察Transformer整体结构。
在Transformer中,注意力机制也有很多种,比如:自注意力机制,掩码自注意力机制,多头注意力机制和交叉注意力机制。本节和下一节都会进行一一讲述。
自注意力机制
最简单的注意力机制对一段输入input(Batch_size, seq_len, d_model)(其中Batch_size是一个批次中,语句的数量;seq_len则是一个句子中包含多少个token;d_model则是模型支持的维度),经过三个相同大小(
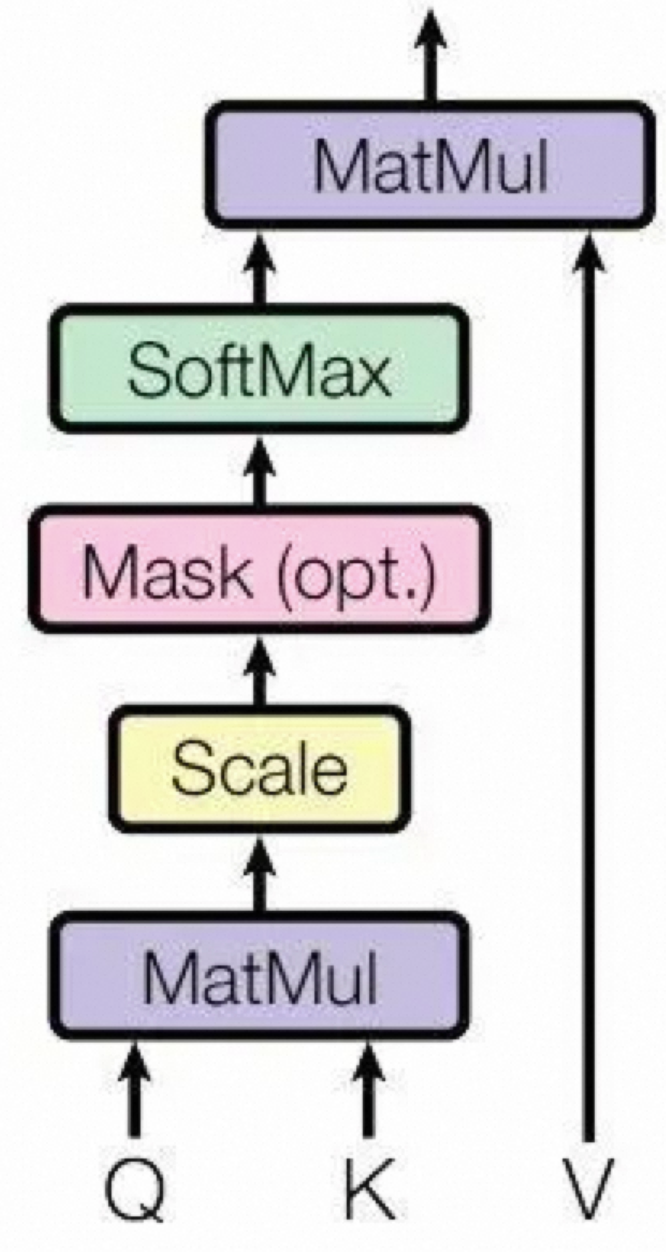
自注意力机制:
在注意力机制中,主要使用的是点积作为相似度函数,计算每个query和key向量之间的关联程度。相似的query、key向量会有更大的点积。但点积可以产生任意大的数字,破坏训练的稳定性。需要乘以一个缩放因子来标准化他们之间的方差,除以
Python
# Define Scaled Dot Product Attention
class Attention(nn.Module):
def __init__(self, head_size: int):
super().__init__()
self.d_model = d_model
self.key_layer = nn.Linear(in_features=self.d_model, out_features=self.d_model, bias=False)
self.query_layer = nn.Linear(in_features=self.d_model, out_features=self.d_model, bias=False)
self.value_layer = nn.Linear(in_features=self.d_model, out_features=self.d_model, bias=False)
def forward(self, x):
q = self.query_layer(x)
k = self.key_layer(x)
v = self.value_layer(x)
# Scaled dot product attention: Q @ K^T / sqrt(d_k)
weights = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
weights = F.softmax(input=weights, dim=-1)
out = weights @ v
return out多头注意力机制
单头注意力机制只是在一个投影空间中计算Query-Key的相关性,多头注意力机制通过不同的线性变换,将输入映射到多个子空间中,每个子空间学习不同的语义关系(语法,句法,语义)。不同的注意力头可以专注于不同的依赖,有些头更关注临词,局部依赖。有些头捕捉远距离依赖。多头注意力可以相当于并行化专家,综合得到更丰富的上下文表示。
📌 多头注意力机制完整代码实现(点击展开)
Python
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, max_seq_len: int = 1024):
super().__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads # 每个头的维度
# 线性投影层(共享输入,分别生成 Q, K, V)
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, d_model, bias=False)
self.v_proj = nn.Linear(d_model, d_model, bias=False)
# 输出投影层(将拼接后的多头结果映射回 d_model)
self.out_proj = nn.Linear(d_model, d_model, bias=False)
# 注册因果掩码(下三角矩阵),用于 decoder 防止信息泄露
self.register_buffer('tril', torch.tril(torch.ones(max_seq_len, max_seq_len)))
def forward(self, x, mask=None):
B, T, C = x.shape # Batch, Sequence Length, Embedding Dim
# 1. 线性投影得到 Q, K, V
q = self.q_proj(x) # (B, T, d_model)
k = self.k_proj(x) # (B, T, d_model)
v = self.v_proj(x) # (B, T, d_model)
# 2. 分割为多个头:reshape + transpose → (B, num_heads, T, head_dim)
q = q.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.num_heads, self.head_dim).transpose(1, 2)
# 3. 缩放点积注意力
scores = q @ k.transpose(-2, -1) / math.sqrt(self.head_dim) # (B, num_heads, T, T)
# 4. 应用因果掩码(仅用于 decoder 风格)
if mask is None:
# 默认使用因果掩码(如 GPT)
scores = scores.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
else:
# 支持自定义 mask(如 encoder 的 padding mask)
scores = scores.masked_fill(mask == 0, float('-inf'))
# 5. Softmax 归一化
attn_weights = F.softmax(scores, dim=-1) # (B, num_heads, T, T)
# 6. 加权聚合 Value
out = attn_weights @ v # (B, num_heads, T, head_dim)
# 7. 合并多头:transpose + reshape → (B, T, d_model)
out = out.transpose(1, 2).contiguous().view(B, T, self.d_model)
# 8. 最终线性投影
out = self.out_proj(out)
return out多头注意力是标注的Transformer使用的,每一个Attention head都有独立的
在逐步发展中现在有了新的多头机制:
| 方法 | Q head | KV head | KV cache 大小 | 代表模型 |
|---|---|---|---|---|
| MHA | 32 | 32 | 1× (基准) | GPT-3 |
| GQA | 32 | 8 | 0.25× | LLaMA-2-70B |
| MQA | 32 | 1 | 0.03× | PaLM |
| MLA | 32 | 压缩 | ~0.06× | DeepSeek-V2 |
MQA(Multi-Query Attention,多查询注意力):每个 head 仍然有独立的 Q(保持模型表达能力),所有 head 共享一份 K/V,显存占用从 O(hLd)→O(Ld),KV cache 更小,推理更快,表达能力稍微下降
GQA(Grouped-Query Attention,分组多查询注意力):MHA,MQA 之间的一种折中方案,将多个 head 分成 g 个组,每组共享一份 K/V,Q 独立
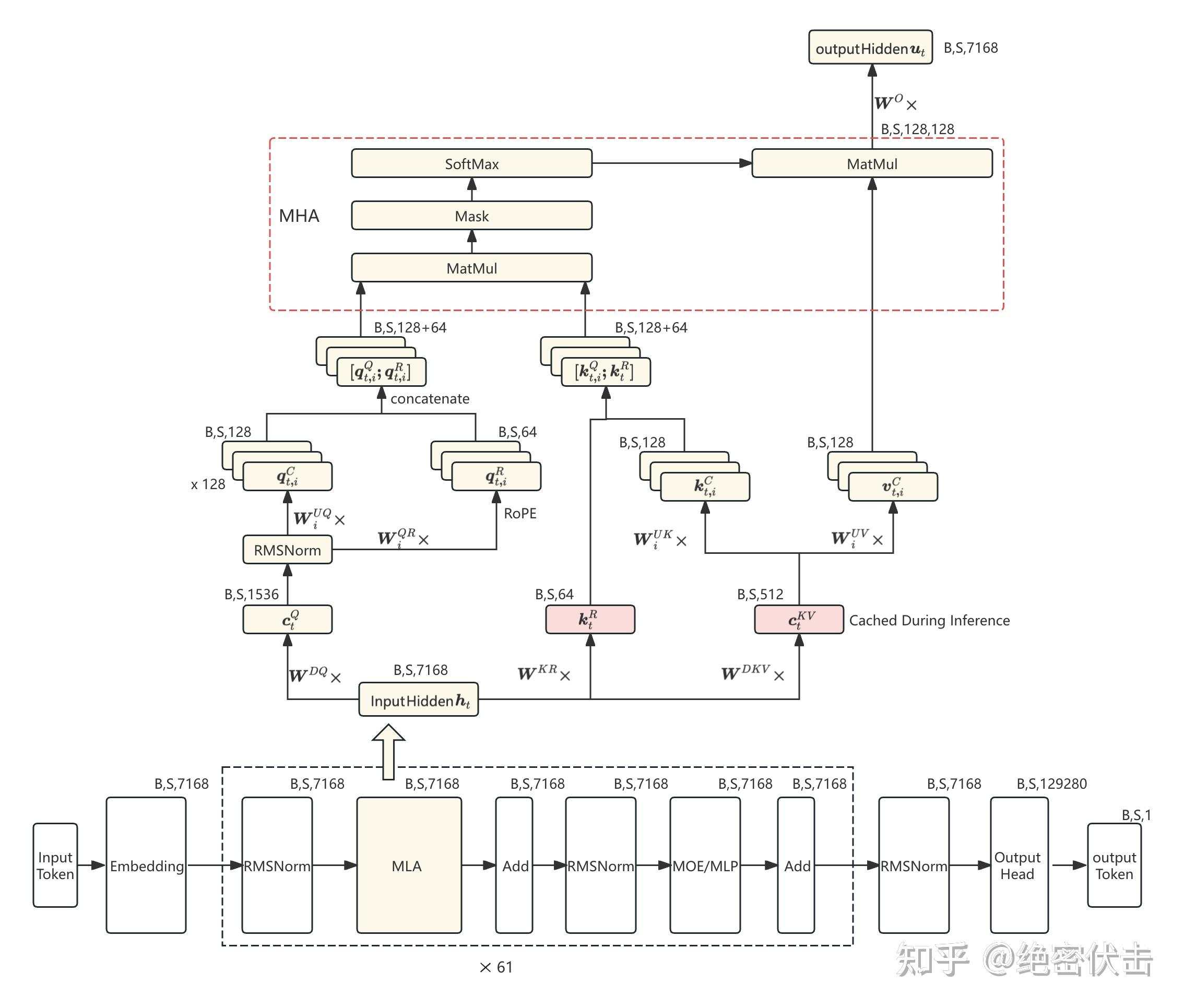
MLA(Multi-Head Latent Attention,多头潜变量注意力):压缩Key/Value,按需恢复。在MLA中,面对K = W_k * h,V = W_v * h的情况,它是将h映射到一个低纬潜变量空间:c = W_latent * h,只缓存这个低纬的潜变量。按需解压成多头 KV,在进行注意力计算时,再通过一组上投影矩阵,把这个潜变量解压成每个头对应的 K/V,保留多头注意力的表达能力,减少 KV 缓存。解耦位置编码,改进 RoPE,将潜变量拆分成两部分,一部分包含位置信息,一部分不包含,可以在压缩过程中保留位置信息而不破坏语义。
MLA整体思路类似Lora,通过两个低秩矩阵,将中间向量存储下来。
MLA的公式如下,
Query向量:
Query向量也先压缩后还原的思路是为了和K、V保持一致性
Key向量:
其中方框里的是需要cache的中间结果,一个是压缩后的向量,用来还原K、V,另一个则是原始输入经过RoPE的k向量,用来记录位置。
Value向量:
输出:
Transformer
了解大模型输入的处理和内部Attention的原理,现在可以看Transformer的整体架构
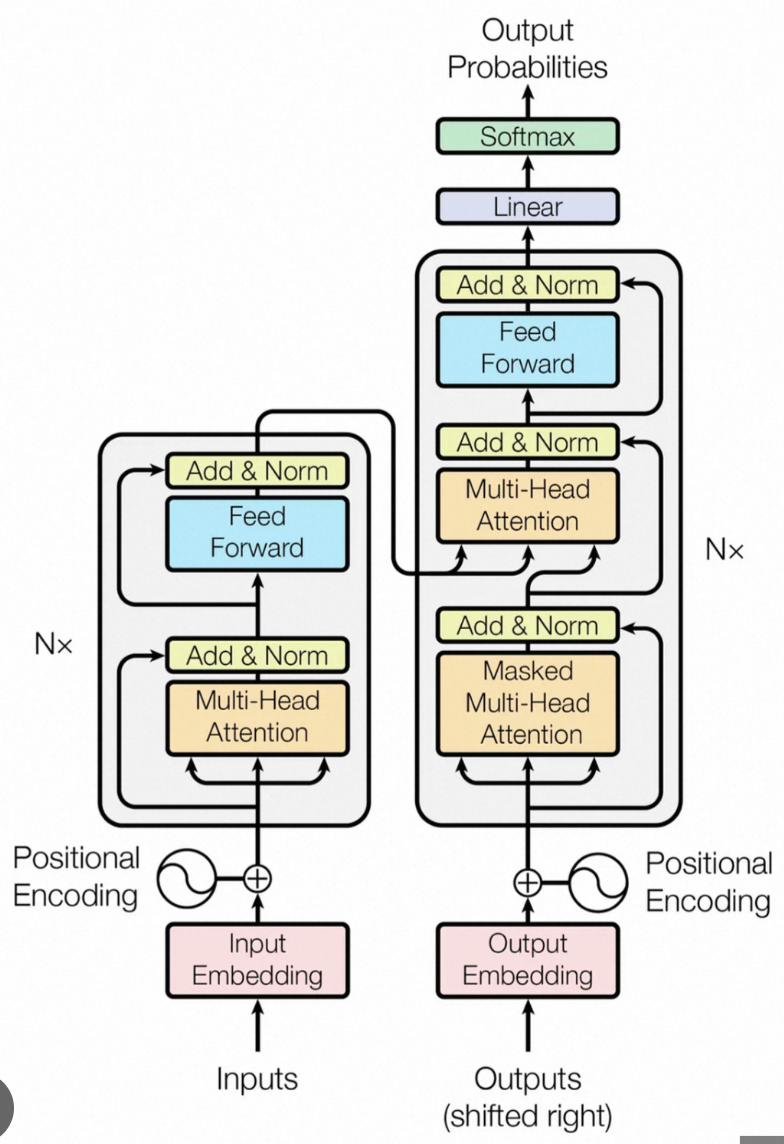
Transformer主要由两部分组成,一部分是左侧的Encoder,另一部分是右侧的Decoder。他两既可以独立运行,也可以合作处理文本任务。本小节先讨论Encoder,Decoder特殊的地方,再讨论他两所具有的共同点。
Encoder
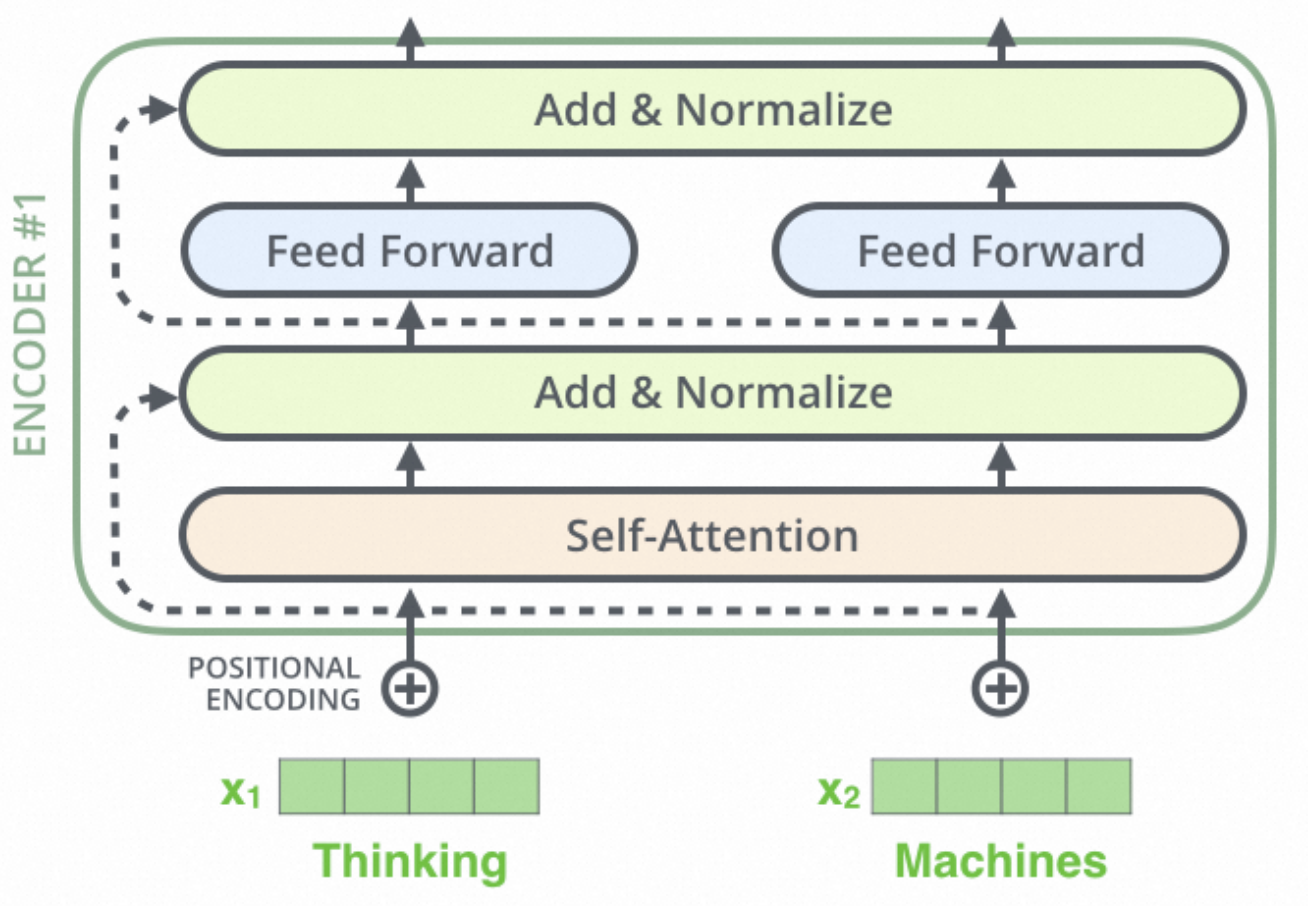
Encoder的作用是提取一个具有更多特征的词向量,Encoder-only的训练目标是掩码语言建模(MLM),随机mask一些token,预测被遮盖的内容。双向上下文表示,对句子的理解更强,适合判别,摘要,文本翻译等任务。
在Encoder中起作用的注意力机制就是最简单的注意力机制。
Decoder
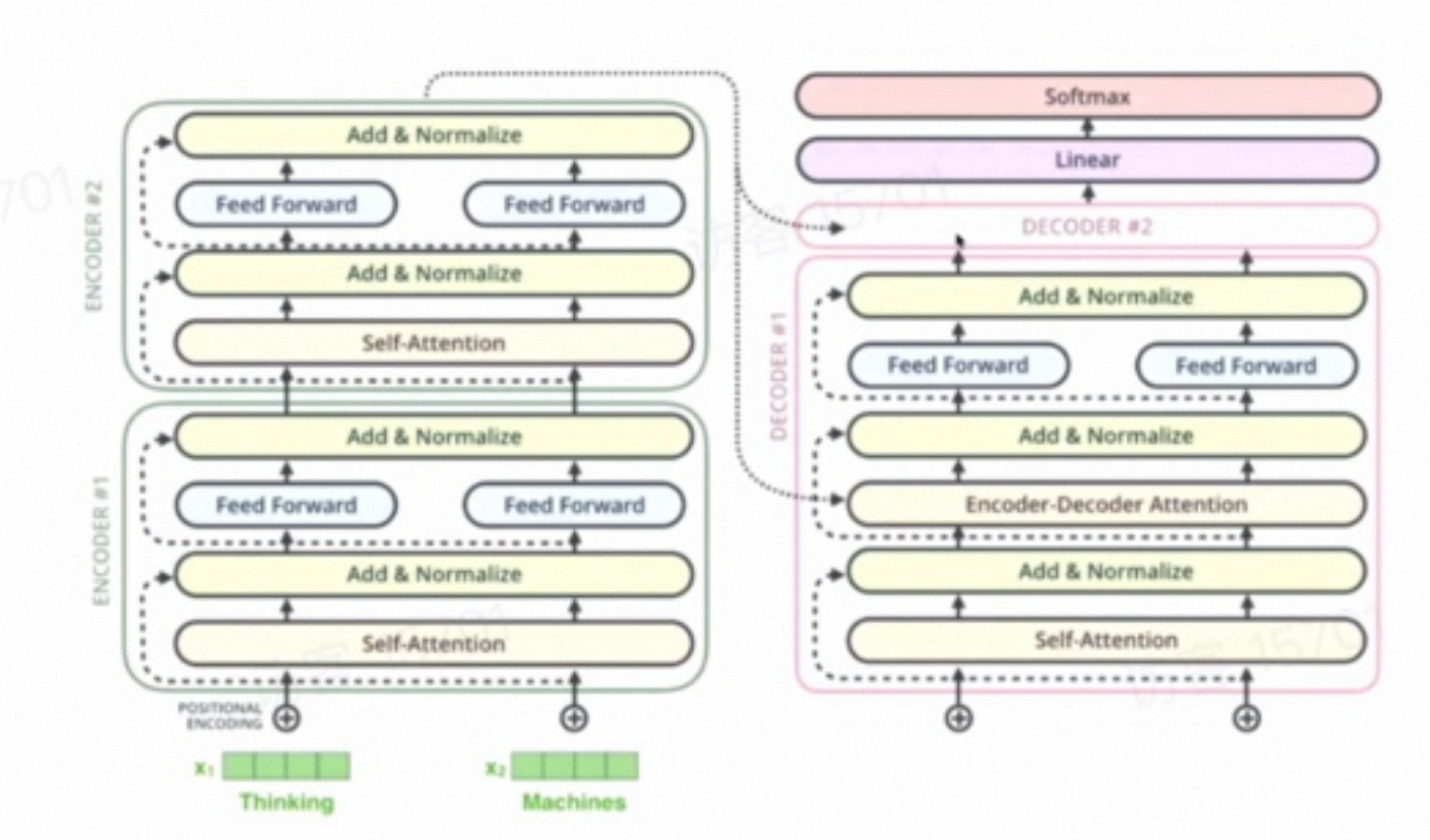
Encoder的作用提取一个具有更多特征的词向量,而Decoder则是利用Encoder提供的词向量,进行下一步的预测、生成。自回归语言建模,自左向右逐个生成。
Decoder的注意力机制由两部分组成:1. 掩码自注意力机制,2. 交叉自注意力机制。
掩码注意力机制中,掩码通过两部分组成:填充掩码(padding),告诉模型哪些位置是有效的,统一输入序列的长度;因果掩码(上三角掩码),Decoder在文本生成时是自回归的方式,预测当前词只能依赖于已经生成的词,可以防止信息泄露。
交叉注意力机制较为简单,即该注意力中
残差连接,FFN
残差连接可以确保梯度能够有效回传,避免梯度消失。
归一化则稳定了每一层的激活值分布,确保了模型训练的稳定性和效率,防止梯度爆炸。
Feed Forward,注意力重点在于线性变换,类似信息整合;而前馈层引入非线性,信息加工。
第一层线性变换(W1,b1):
通常会将输入的维度进行拓展。模型的隐藏层纬度是 dmodel(比如 512),第一层可能会将其映射到一个更高的维度,比如 4*dmodel
该步骤可以看作是将特征映射到更高维空间,以便进行更复杂的非线性变换,学习更多特征
非线性激活函数
- 如 ReLU 或 GELU,引入非线性,使得网络能够学习和表示更复杂的模式
第二层线性变换(W2, b2):
将维度映射回原始的 dmodel 维度
将高维空间中处理过的特征重新映射回模型的标准维度,以便与后续层(残差连接)兼容
以下是现在大模型中常见的FFN形式,第一个是SwiGLU激活函数,只是替换激活函数;第二个是MoE结构,用于替换整个FFN层。
SwiGLU激活函数由两部分组成:GLU(Gated Linear Unit)和Swish(SiLU)。
GLU包含两个线性变换,其中一个经过Sigmoid激活函数后作为门,用来控制另一个线性变换的输出
GLU可以让网络学会选择性的让信息通过,如果Gate的输出接近0,信息就被阻断,接近1,信息通过。而在Transformer的FFN中,通常省略偏置项。
Swish是自门控激活函数,公式为:
在x小于0的区域不完全为0,允许少量负梯度流过,有助于训练稳定性。
SwiGLU是通过将GLU公式中的激活函数换成了Swish:
使用三个矩阵,为了保持参数量和计算量与标准Transformer相同,通常将中间的维度从4d降低到8/3d
优势:
门控机制,更强的表达能力:引入乘法交互,传统ReLU只能简单把负值切断,SwiGLU允许模型通过两个线性变换的逐元素相乘来学习更复杂的特征交互。让神经元具有了“选择重要特征”能力
更平滑梯度:ReLU在0点不可导,且负半轴梯度为0。SiLU是处处可导的平滑曲线,使得梯度在下降过程更加顺滑,模型更容易收敛,能缓解梯度消失问题
MoE
让不同的专家处理不同的任务或输入,每次只激活最相关的几个专家。专家=一个前馈神经网络(FFN),门控网络=一个小型网络,决定输入该路由给哪些专家。一般由几个大专家+每次路由得到的细粒度专家组成
一个典型的 MoE 层可以在 Transformer 中替换标准的 FFN 层,包括:
Gating Network(门控网络),输入当前 token 的表示向量,输出每个专家的权重或置信度,表示该专家对输入的重要性,常用 Top-k 门控
Experts(专家),多个相同的前馈网络(FFN),每个专家独立处理被分配到它的输入
Routing(路由),根据门控输出,将输入分发给 top-k 个专家,专家处理后,结果按权重加权求和
在MoE训练中,容易遇到专家坍缩问题,即所有token都路由到同一个专家,因此需要加入辅助损失来鼓励均衡路由:
归一化
归一化则稳定了每一层的激活值分布,确保了模型训练的稳定性和效率,防止梯度爆炸。最本质的作用是稳定训练过程,解决的网络训练中一个关键问题:内部协变量偏移(Internal Covariate Shift)。
内部协变量偏移:当一个深度神经网络层接收输入时,这些输入会随着前一层参数的更新而不断变化。如果一个层的输入分布在训练过程中一会变得很大,一会变得很小,或者一会集中某个区域,一会分散开。会带来以下影响:
影响激活函数:这会导致激活函数(Sigmoid, Tanh)的输入落入饱和区(梯度非常小的区域),从而导致梯度消失,让模型参数难以更新,学习停滞。
影响优化器:不稳定的输入分布会使得损失函数的曲面变得崎岖不平,优化器在寻找最小值变得困难,容易剧本震荡,导致收敛速度变慢。
作用:
稳定梯度:确保激活函数的输入始终在非饱和区,防止梯度爆炸或消失,使梯度流动更流畅
加速收敛:使损失函数曲面变得更平滑,让优化器能更快、更稳定地找到最优解
允许更大的学习率:由于梯度稳定,模型可以承受更大的学习率,加速训练
常见的归一化策略主要有BatchNorm,LayerNorm,RMSNorm
Batch Normalization(BN)对一个批次(batch)内的所有样本在同一特征维度上进行归一化。但同一batch内不同样本的同一位置的token语义完全不同(第五个token可能是动词,也可能是名词),batch层面归一化无意义。
设一个 batch 的数据大小为
- 计算该特征维度在当前 batch 上的均值
- 计算该特征维度在当前 batch 上的方差
- 归一化(标准化)
其中
- 缩放和平移(仿射变换)
其中
Layer Normalization(LN)是对每个样本的每个特征纬度进行归一化
对于一个向量$\mathbf{x} = [x_1, x_2, \dots, x_d]^\top \in \mathbb{R}^d $,其逐元素统计量(按维度计算,即对向量本身求均值/方差)定义如下:
均值(Mean):
RMSNorm去中心化操作,只有缩放操作,只需要计算方差计算量更小。
对于向量
将每个分量
解码策略
贪婪解码:在每一步,模型都选择当前词表中概率最高的那个词作为下一个词
Top k抽样:不只选择概率最高的词,而是从模型预测的概率分布中,只考虑概率最高的 K 个词,从这 K 个词中随机采样一个作为下一个词
Top p抽样:不再固定选择 K 个词,而是选择一个最小的词集,让这些词的累积概率超过一个预设阈值 p,然后从这个词集中随机采样一个词
温度系数
温度系数
当 T>1 时,Z/T 的值会变小,大的更小,小的更大,概率分布变平坦,增加低概率词被选中的机会,增加多样性,适合生成比较具有创意性的内容,比如内容生成、写作
当 T<1 时,Z/T 的值会变大,大的更大,小的更小,概率分布更尖锐,高概率词被选中机会增加,减少多样性,适合代码生成、问答系统、机器翻译等确定性高的任务
当温度系数为0时,模型默认采用贪婪解码。
从数学的角度上讲,温度系数
由于分母不能为0,所以在工程实现中,温度系数为0,底层代码会跳过随机采样逻辑,执行贪婪解码。
同时不能说温度系数为0就是贪婪解码,因为在现代大模型中,解码策略往往是top k,top p等策略混合执行,存在默认值。所以温度系数为0的时候,top k,top p等策略也不应该起作用。
损失函数
前面几节是一组输入进入Transformer经过一系列的变化后,输出的维度仍然是(Batch_size, Seq_len, d_model),然后经过一步Linear,变为(Batch_size, Seq_len, vocab_size),然后经过softmax变为概率输出logits。这里由于Seq_len的存在,配合前面的mask操作,可以实现一句话多次学习,而不是只学习最后一个token的输出。
本节损失函数主要介绍decoder-only。建模目标就是:希望模型输出什么,损失函数用于衡量模型距离目标的远近。
目标:最大化似然
损失函数:交叉熵
Decoder-only结构创新
当前主流的大模型几乎全部采用 Decoder-only 架构。相比原始 Transformer 的 Encoder-Decoder 结构,Decoder-only 移除了 Encoder 和交叉注意力,只保留带因果掩码的自注意力 + FFN。本节梳理从 GPT 到当前 SOTA 模型在架构层面的关键创新。
为什么 Decoder-only 成为主流
- 自回归天然适配生成:语言生成本质上是逐 token 的条件概率建模
,Decoder-only 的因果掩码天然匹配这一目标 - Scaling Laws 的支持:OpenAI 和 DeepMind 的 Scaling Laws 实验表明,在相同计算预算下,Decoder-only 模型的 loss 下降效率优于 Encoder-Decoder
- 工程简洁性:只需因果掩码,不需要管理 encoder 的双向 attention 和 cross-attention 的复杂交互,分布式训练更简单
- 统一的 prompt 范式:通过 In-Context Learning,一个模型可以处理翻译、摘要、问答等各种任务,无需针对不同任务设计不同的 encoder 输入格式
Pre-Norm vs Post-Norm
原始 Transformer 采用 Post-Norm:先做 Attention/FFN,再做 LayerNorm。
GPT-2 之后主流模型全部改用 Pre-Norm:先做 LayerNorm,再做 Attention/FFN。
Pre-Norm 的优势:
- 训练更稳定:残差连接直接连通输入和输出,梯度可以无损回传到底层,不容易出现梯度消失/爆炸
- 不需要 warmup:Post-Norm 在训练初期容易不稳定,通常需要较长的学习率 warmup,而 Pre-Norm 对学习率不敏感
- 深层网络更友好:当模型层数增加到 80+(如 LLaMA-65B),Post-Norm 几乎无法收敛
代价是 Pre-Norm 的理论表达能力略弱于 Post-Norm(每层的归一化会"压缩"残差分支的影响),但实践中大规模训练的稳定性收益远大于这一损失。
LLaMA 架构:当前开源标准
Meta 的 LLaMA 系列确立了当前开源模型的事实标准架构,几乎所有后续模型(Qwen、Mistral、Yi、Baichuan 等)都沿用这一设计:
| 组件 | 选择 | 替代方案 |
|---|---|---|
| 归一化 | RMSNorm (Pre-Norm) | LayerNorm |
| 位置编码 | RoPE | ALiBi、绝对位置编码 |
| 激活函数 | SwiGLU | GELU、ReLU |
| 注意力 | GQA (70B) / MHA (7B/13B) | MQA |
| 偏置项 | 全部移除 (bias=False) | 保留 |
| 词表 | SentencePiece (32K) | BPE |
关键设计决策解析:
移除所有偏置项:LLaMA 在所有线性层(包括 QKV 投影、FFN、lm_head)中移除了偏置项。原因是在大规模模型中,bias 对模型表达能力的贡献微乎其微(相比数十亿权重参数,几千个 bias 参数可以忽略),但移除后可以简化计算、略微减少参数量,并且让 RMSNorm 的"零均值假设"更合理。
SwiGLU 的 8/3 维度:标准 FFN 中间维度是 4d,但 SwiGLU 有三个权重矩阵(门控 + 上投影 + 下投影),为了保持参数量一致,中间维度调整为
DeepSeek-V2/V3 架构创新
DeepSeek 系列在 LLaMA 架构基础上做了两项重大创新:
1. MLA(Multi-Head Latent Attention)
前文已详细介绍 MLA 的公式。其核心创新在于:用一个低秩压缩向量
2. DeepSeekMoE(细粒度专家 + 共享专家)
传统 MoE(如 Mixtral)使用 8 个大专家,每次激活 2 个。DeepSeek 提出:
- 细粒度专家:将专家数量从 8 个增加到 256 个,每个专家更小,每次激活 8 个。更细粒度的路由允许更灵活的知识组合
- 共享专家(Shared Expert):设置 2 个始终激活的共享专家,处理所有 token 的通用知识(语法、常见模式),避免每个路由专家都冗余学习这些基础能力
- 路由公式:
其中
DeepSeek-V3 (671B 总参数,37B 激活参数) 的配置:256 个路由专家 + 1 个共享专家,每次激活 8 个路由专家。
Mixture of Experts 训练挑战
MoE 架构在训练中面临独特挑战:
专家塌缩(Expert Collapse):如果不加约束,门控网络倾向于将所有 token 路由到少数几个专家(因为这些专家因训练更多而变得更强,形成正反馈循环),导致其余专家几乎不被使用。
负载均衡损失:为解决专家塌缩,在训练 loss 中加入辅助损失:
其中
通信开销:在分布式训练中,不同 GPU 上的 token 需要路由到不同的专家(Expert Parallelism),涉及 All-to-All 通信,网络带宽成为瓶颈。DeepSeek-V3 通过限制每个 token 最多发送到
长上下文扩展
基础模型通常在 4K-8K 上下文长度上训练(因为注意力的
Position Interpolation (PI):将位置索引线性缩放到训练长度范围内。如训练 4K,要推理 16K,则将位置
NTK-aware Scaling:不是缩放位置,而是修改 RoPE 的 base 频率。将
YaRN(Yet another RoPE extensioN):结合 NTK scaling 和注意力 softmax 的温度修正,是目前效果最好的无微调外推方法之一。
实际工程中,长上下文模型通常采用两阶段训练:先用短上下文(4K-8K)训练主体,再用长上下文数据(32K-128K)进行少量 continuation training。
Decoder的训练
第一节主要介绍了Transformer的结构和原理,并没有涉及将其放置于显卡上进行训练,所以本节主要聚焦于模型在显卡上的训练情况以及可能会遇到的问题。
当前阶段主流的大模型是Decoder-only模型,目标是自回归语言建模,让大模型学会文字接龙。对比标准的Transformer,Decoder-only内部是只有掩码自注意力机制和FFN,没有交叉注意力机制。互联网上本身就存在海量适用于预训练的无监督语料。
显存占用
显存在大模型领域至关重要,理解显存的组成成分也非常重要。在介绍显存占用时,先考虑全量微调,即所有参数都要更新。
显存占用第一点:模型参数,对于一个30B,FP32的模型,加载进显卡,需要占用30*2=60GB的显存。
显存占用第二点:梯度,梯度用来更新模型参数,可以理解要更新多少参数,就需要保有多少梯度,它两大小一般一致。
显存占用第三点:优化器状态,优化器是利用梯度来更新模型参数,不同的优化器所需要的空间大小不同,一般是1~2倍的模型参数大小。优化器状态是指优化器为了执行参数更新而额外维护的中间变量,如一阶动量、二阶动量。
显存占用第四点:激活值,在模型训练阶段,前向传播产生的中间层激活值需要完整地保存在显存中。原因在于反向传播:在计算梯度以更新模型过程中,需要利用前向传播中产生的中间激活值,根据链式法则,每一层的梯度依赖于后一层的梯度和该层的激活值。为了完成梯度计算,从输入层到输出层的所有激活值必须保留在显存中,直到在反向传播中使用完毕。
优化器Optimizer
在深度学习中,优化器就是反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数不断逼近全局最小。
优化器核心思想,使用梯度下降进行优化,整个过程中重点关注:优化方向,决定前进方向是否正确,反应为梯度;步长,决定每一步多远,在优化器中反应为学习率。
梯度(Gradient)详解:梯度是损失函数对模型参数的偏导数,表示“当前点损失函数变化最快的方向”,用于告诉优化器“往哪个方向走能让损失下降”,通过反向传播得到。在GPU中,往往与模型参数形状完全相同,即每个参数对应一个梯度值。
这里为了节省篇幅,只重点介绍Adam,其他可以了解SGD等。
Adam(Adaptive+Momentum)将一阶动量和二阶动量都利用起来。
SGD的一阶动量为:
AdaDelta的二阶动量:
Adam参数更新公式:
通过一阶动量和二阶动量,有效控制学习率步长和梯度方向,防止梯度的振荡和在鞍点的静止
AdamW:原始Adam的权重衰退实现方式有误,与L2正则不等价(在别的优化器中,这两是等价概念,而Adam中不是)。
L2正则化的本质是不让模型的参数数值太过庞大,避免模型激进和过拟合。通过在损失函数中加入惩罚项,统一约束所有参数。
其中
而在Adam中,L2正则化被放入损失函数的计算,由于它是自适应学习率,所以不同情况下L2正则化缩放程度不一样,对参数统一约束没有达成。每个参数受到的“正则力度不一致”
AdamW则是将梯度更新和权重惩罚解耦分开,直接作用于权重更新后。
激活值
激活值是模型在进行前向传播时,每层计算产生的中间输出结果。
训练阶段见上文描述,模型推理阶段,在推理过程中只需要进行一次前向传播,计算最终结果后,中层的激活值可以立即被释放,显存占用相对较小。
Batch_size参数对显存的影响,就来源于激活值的大小,而不是训练数据本身的加载。在模型训练过程中,Batch_size主要在两个地方起作用:1.数据层面(DataLoader),决定每次从磁盘/内存读取多少样本,占系统内存,几乎不占GPU显存;2.计算层面(forward/backward),决定一次前向传播中并行输入样本数量,影响激活张量形状,直接影响显存大小。
分布式训练
分布式训练包含多个阶段,首先第一点是通信算子,例如Allreduce、Allgather等,其次才是模型并行的相关策略,如DP、TP、PP等。
通信算子
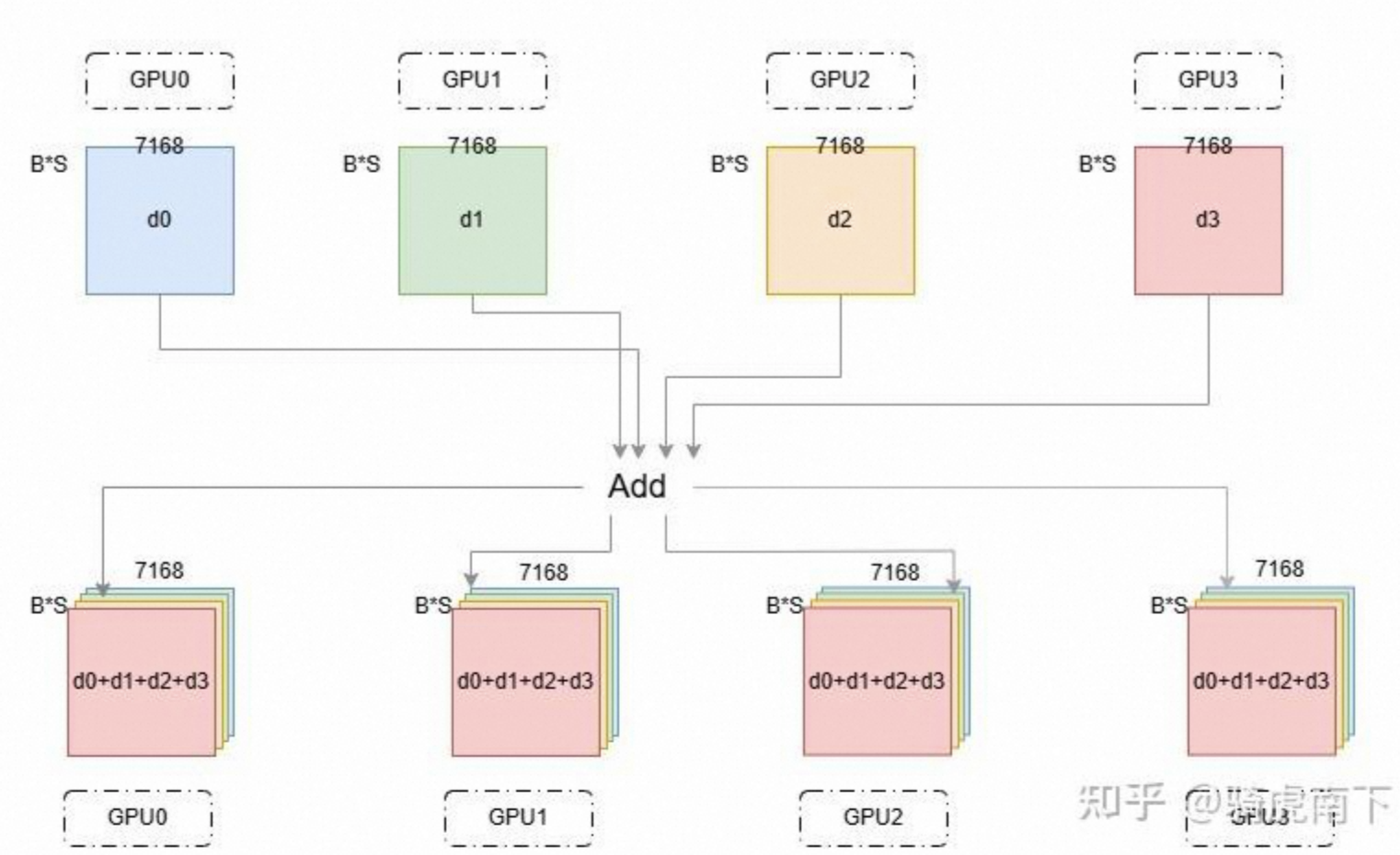
Allreduce主要操作是对应项相加,相加后再发到多个GPU上,类似Torch中的Add算子。如下图所示,可以理解为一份数据集,切分四分,每个GPU一份,计算完自己部分后,相加后得到所有计算,然后更新参数。
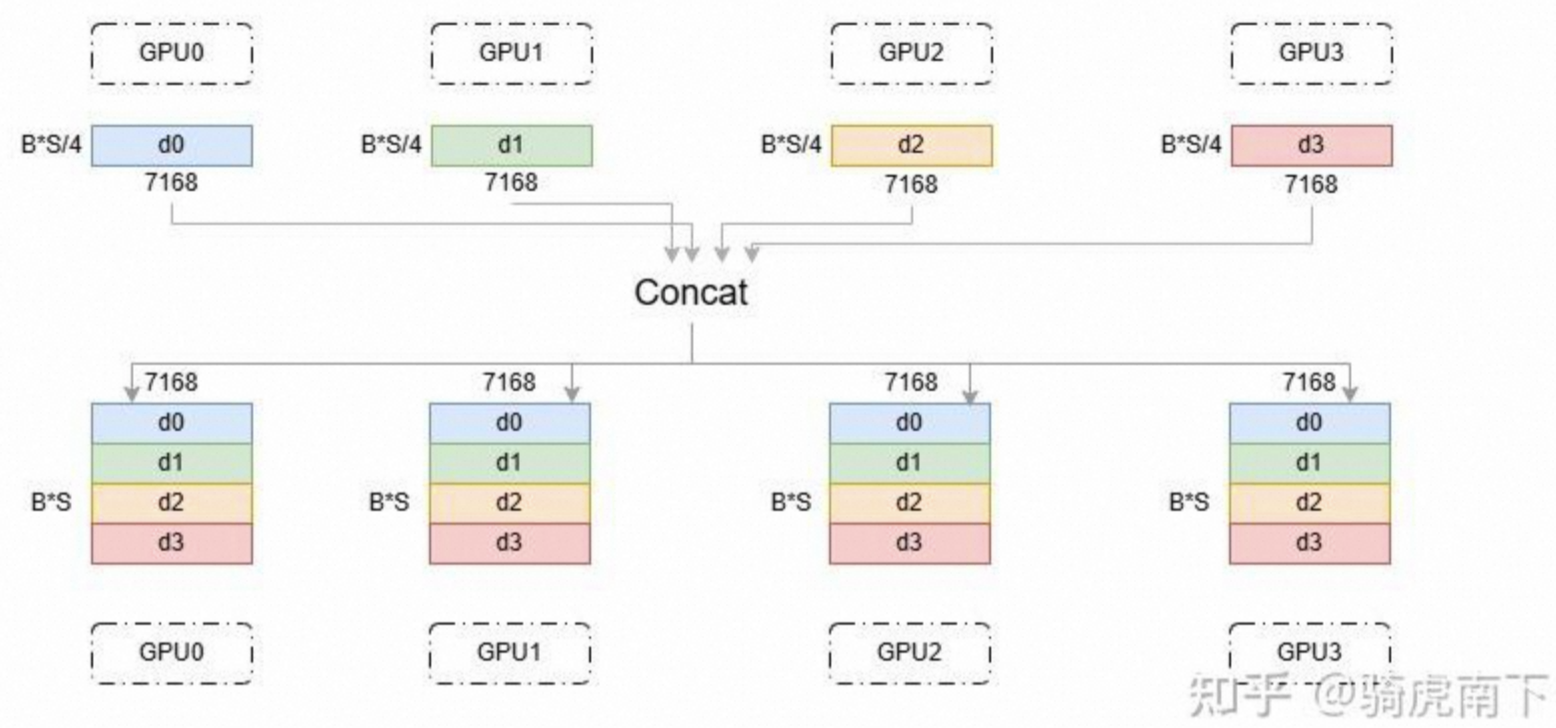
Allgather主要操作是聚合,类似Torch中的Cat算子。如下图所示,则是每个GPU计算一部分数据,数据集完整,然后需要将所有GPU计算的结果进行一个组合,再广播到所有GPU上。
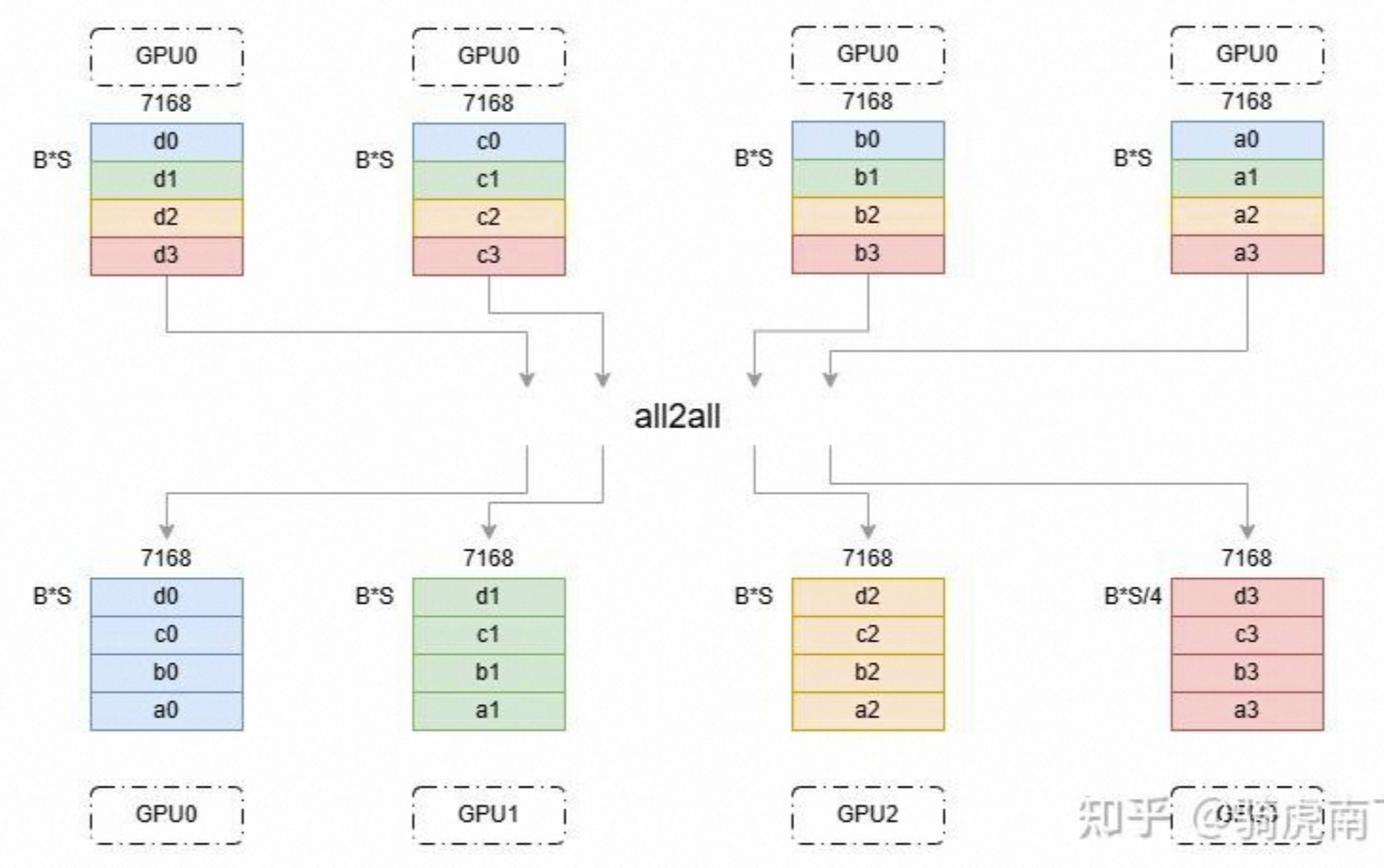
All2All主要应用于MoE框架,本质上是进行一个矩阵转置,把按行分布的数据变成按列分布。每张卡向每张卡发送不同的数据块,由于MoE的路由机制存在。类似Torch中的Transpose算子。下图中可以理解为数字后缀为路由到的GPU节点。
推理并行策略
DP,Data Parallel:CPU从硬盘中读取数据,通过一个CPU进程将数据分为多份,给每个GPU一份。独立运算(前向、反向传播)后,将各自梯度传给GPU0,由GPU0计算更新后的参数,广播到其他GPU。
DDP,DIstributed Data Parallel:集群通讯方式,Ring-AllReduce。Step 1. scatter-reduce,同时发送和接收,最大限度利用每个显卡的上下行带宽。scatter: 通过分发让每个节点有不同的值,reduce:收集所有节点的值并计算。Step 2. 传播已经有的梯度。其中DDP是多进程,每个进程为自己的GPU准备数据。
TP,Tensor Parallel:张量并行,将模型的每一层分隔到不同GPU上执行,用户请求会在GPU间流转,最终结果重新组合。计算理论基础是矩阵的分块运算,该运算结果不会改变最终计算结果。例如线性层的切分
SP,Sequence Parallel:序列并行,是将长序列切分为多个片段,分配到不同GPU设备上并行处理的策略并行策略。
PP,Pipeline Parallel:将模型按层拆分到不同设备,设备以流水线方式在不同设备间顺序流动处理。整体上可能会导致部分显卡闲置。
DeepSpeed
| 阶段 | 分片内容 | 每 GPU 显存 | 通讯量 |
|---|---|---|---|
| ZeRO-1 | 优化器状态 | ~模型×6(省优化器) | ≈ DDP |
| ZeRO-2 | + 梯度 | ~模型×2(省梯度+优化器) | ≈ DDP |
| ZeRO-3 | + 模型参数 | ~模型×4/N(全切) | 1.5× DDP |
ZeRO-1: 优化器状态分块:通讯量与DDP相同。每个GPU负责更新一部分参数,其余GPU计算梯度发送后就抛弃(发送,计算并行),GPU拿到分块优化器对应参数的梯度均值。更新后的参数需要广播到其他GPU,训练一次完成。减少GPU显存占用,但不怎么增加GPU的通讯量。但在计算时仍拥有完整的模型参数和梯度。
ZeRO-2: 梯度分块:反向传播计算梯度,以梯度的形式发送并更新,其他显卡不保留不属于他部分的梯度。
ZeRO-3: 参数分块。前向时 AllGather 拉取所需参数,反向时 AllGather + ReduceScatter 同步梯度,用完即释放。
FlashAttention
本节针对FlashAttention是通过算法角度,重点理解其优化点,而非具体的分块等算法。
Background
标准的Transformer注意力机制的时间复杂度和空间复杂度会随着序列长度
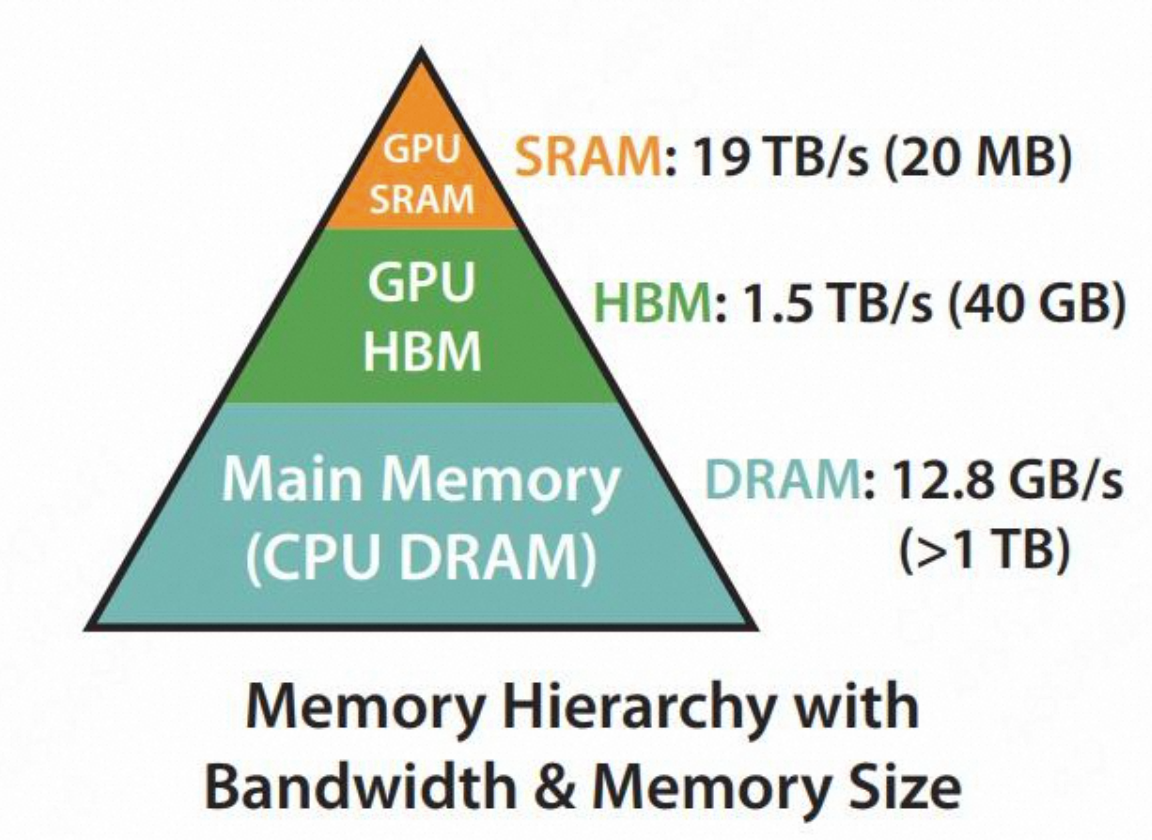
现在显卡中的计算主要受限于两个方面:计算瓶颈和访存瓶颈,而显卡目前发展为计算较快,使得显存带宽成为限制计算速度的重要因素。而在标准的Attention计算中,显存需要先将
前向传播:算子融合
由于标准注意力机制频繁的读写,导致整个流程会被显存带宽卡住。
FlashAttention选择将三个分开的步骤,乘法、softmax、乘法(
**而在这个过程中的softmax操作与标准的softmax有区别,FlashAttention做了专门的优化,本节不做赘述,应该不是算法的重点。FA 的 Softmax 叫做 Online Softmax,因为数据是分块进来的,所以需要边算边更新全局最大值进行 Rescaling 缩放。**当一块新数据进来时,如果发现新的全局最大值,可以对之前算好的部分进行一个修正。
反向传播:反向重计算
在大模型训练中,还需要反向传播来更新梯度。在反向传播计算梯度时,根据微积分的链式法则,你需要用到前向传播时产生的中间变量。所以在标准的 Attention 中,为了能算梯度,刚才提到的那两个巨大的中间矩阵
FlashAttention选择不存储
而在反向传播阶段,需要用到
FlashAttention是精确计算,算出来的结果和标准Attention没有任何精度差异。
同时Transformer随着序列长度N的增加,计算成本、存储成本都是
SFT微调
经过海量无监督数据和无数显卡集群的大规模训练,大模型学会了文字接龙,它具备了海量的知识储备和逻辑能力,但它缺乏稳定的指令遵循能力。所以需要构造微调数据集(有标注的自然语言形式的数据),对模型参数进行微调,使模型具备指令遵循能力。
指令微调与预训练类似,但其目标函数只针对输出部分来计算损失。
在模型具备指令遵循能力的情况下(往往开源项目中拿到的模型也是这种),可以通过高效模型微调(PEFT,Parameter Efficient Fine-tuning),配合专业领域的微调数据集,微调模型成为一个垂域大模型。
数据形式以问答对为主,损失函数依旧是交叉熵,只针对“回答部分”的损失,不计算prompt部分的损失。实现方式则是通过将labels中prompt对应位置设置为-100,框架在处理过程中会自动忽略这些位置。
LoRA(Low-Rank Adaptation of Large Language Models)
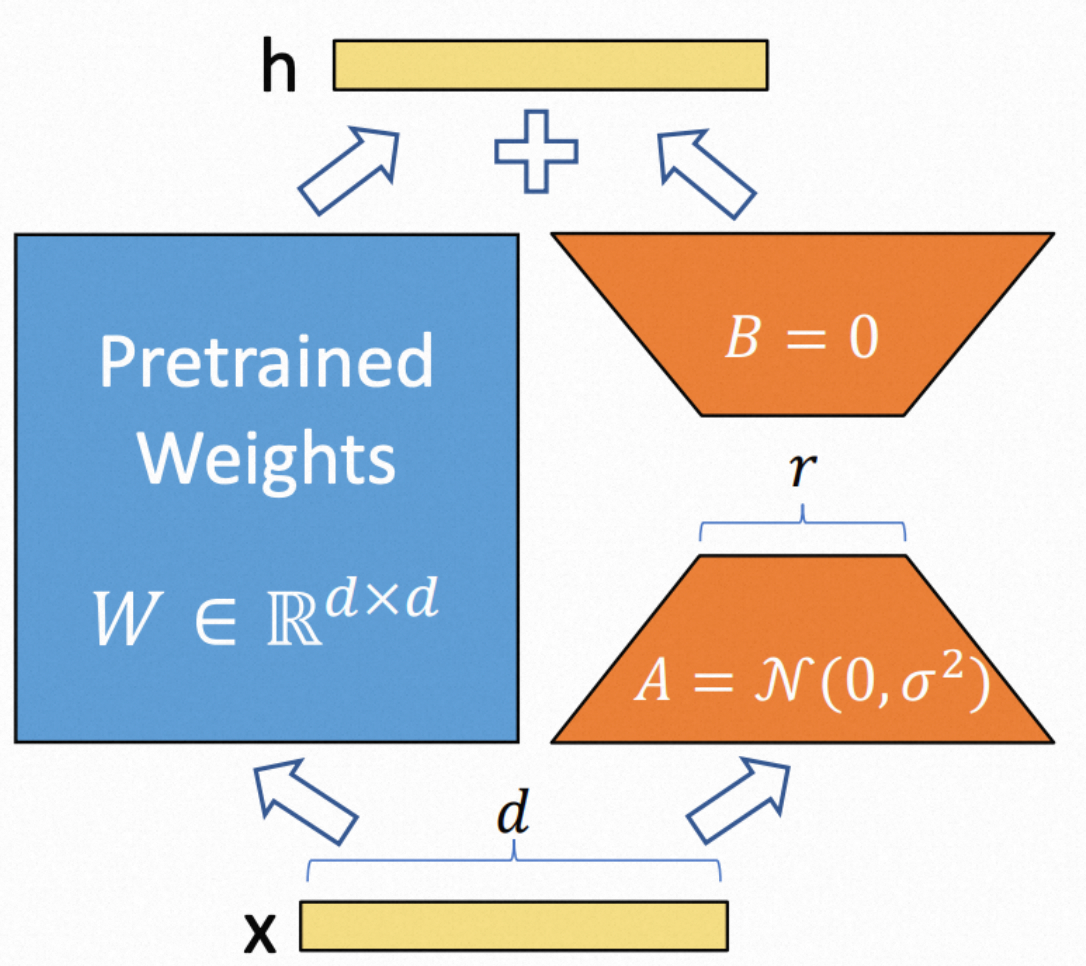
LoRA冻结模型中原本的参数,通过添加两个小的矩阵,实现微调的效果。在全量微调中,其参数量与预训练的参数量相同,且注意力权重矩阵存在大量冗余信息,可以通过线性代数的特性进行降维。其中A矩阵大小(d_model, r),使用随机高斯初始化,B矩阵大小(r, d_model),使用零初始化。
LoRA在训练过程中的可以配置的参数:
r:rank,低秩维度,用来确定A、B矩阵分解的大小。任务越复杂建议r越高
lora_alpha:缩放系数,放大或缩小低秩更新的强度,控制LoRA更新量的整体强度。常见设置alpha=r或alpha=2r
lora_dropout:加在lora分支上的dropout
target_modules:lora理论上可以添加到任意线性层中,但在Transformer中常常加在注意力层中q_proj,k_proj,v_proj,o_proj
电车就选特斯拉,手机就选苹果,微调就选lora
一个进行0初始化,一个进行高斯初始化。保证在最开始的时候低秩矩阵输出是0,对模型结果没影响。
反过来,A=0,进入到低秩瓶颈层的中间特征全部为0,在训练初期中间层完全没有捕捉到输入的任何信息。让A随机化可以保证输入特征被输入到一个随机的低秩空间,虽然B=0阻断输出,但只要B开始更新,模型可以立刻利用A提取的特征进行微调。
在第一步中,根据链式法则,矩阵B的梯度被Ax影响,因为A是高斯初始化,所以不为0,B矩阵进行更新。而矩阵A的梯度被B影响,B为0,所以梯度为0,而A不更新。但在后面步骤中,A、B都可以正常更新。
如果
RL强化学习
Background
马尔可夫决策过程(MDP)
马尔可夫性质表示未来状态只与当前状态(和动作)有关,与过去的历史无关。这使得我们可以用一个状态来完整地描述环境。
**马尔可夫决策过程(MDP)**是一个在“马尔可夫性质”假设下建模序列决策的问题框架,一般用五元组
智能体通过与环境的反复交互(“状态—动作—转移—奖励”的循环),旨在找到一条最优策略
强化学习元素
在强化学习中,我们通常将问题描述为一个马尔可夫决策过程(Markov Decision Process, MDP),它包含以下几个关键元素:
状态(State,S):智能体所处的环境状态
动作(Action,A):智能体在给定状态下可以执行的一系列操作
状态转移:从当前状态
采取动作 后,会以一定的概率转移到下一个状态 奖励(Reward,R):智能体在每个时刻(或每次转移)获得的即时回报,反映了该动作在此状态下的好坏
折扣因子(Discount Factor,
):用于平衡当前奖励和未来奖励的重要性 轨迹(Trajectory):在强化学习中,智能体从环境的初始状态开始,与环境交互直至到达终止状态所经历的一系列状态、动作以及相应的奖励就构成了一条完整的“轨迹”。形式上可以表示为:
经验(Experience):智能体可与环境交互多次,进行多次实验,形成多个轨迹。多个轨迹的集合被称为经验。即
回报(Return):强化学习的目标是学习一个好的策略,智能体按照这样的策略和环境交互,让累积奖励达到最大。这个累积奖励就是回报。
.强化学习的目标是最大化期望回报。 价值函数(Value Function):价值函数衡量的是期望回报,具体分为状态价值函数和动作价值函数。
状态价值函数
动作价值函数
优势函数(Advantage Function):优势函数度量的是,在给定状态
下,执行某个动作 比起在该状态的平均水平(即状态价值)好多少或差多少。它的常见形式是: $ A^{\pi}(s, a) = Q^{\pi}(s, a) - V^{\pi}(s). $ 探索(Exploration)和学习(Learning):强化学习一般分为两个阶段。第一个是探索阶段,智能体先按照某些策略和环境进行交互,形成经验。第二个是学习阶段,智能体按照某些算法,从经验中学习,进而优化自己的策略
行为策略(Behavior Policy)和目标策略(Target Policy):行为策略是智能体在环境交互时实际执行的策略。目标策略是智能体最终想要学到的策略,通常记为
。两个策略相同就是on-policy,否则就是off-policy。核心区别在于:数据采样的策略是否与学习或评估的目标策略相同。
广义优势估计(GAE)
GAE 是一种折中方法,结合了蒙特卡洛(MC)和时序差分(TD)的优点,旨在通过平衡偏差与方差来提高优势函数估计的稳定性和效率。 在计算优势函数中,它主要是用来求解A,V则通过Critic Model得到。
GAE 引入一个超参数
(类似于 TD 中的折扣因子),在计算优势函数时利用 TD 方法的部分信息,而不是完全依赖于真实的回报。 它通过对多步 TD 误差进行加权平均,实现对优势函数的平滑估计,从而减少单步 TD 误差带来的偏差,同时控制方差。
是第 步的 TD 误差; 是折扣因子,控制未来奖励的重要性; 是加权参数,控制 TD 与 MC 的折中程度:
当
Actor-Critic架构
为平衡高方差和低偏差,在 Actor-Critic 方法中将策略函数(Actor)和价值函数(Critic)同时学习:
Actor:输出策略
Critic:估计价值函数
或
每一次采样时,利用 Critic 来估计动作优势(Advantage),更新 Actor 的梯度,使得训练更稳定。
重要性采样基本原理
重要性采样是一种统计方法,用来在目标分布
假设我们希望计算目标分布
如果
其中,
重要性采样允许我们使用与目标分布不同的采样分布,从而
提高采样效率,尤其在
较难采样的情况下; 在强化学习中,它允许我们基于旧策略生成的经验数据来优化新策略,而无需重新采样环境数据。
Reward Hacking
在RL中,由于reward function设置不合理,导致agent只关心累计奖励,而并没有朝着预想的目标优化。在RLHF中,奖励模型每次偏好的数据应该是针对我们优化目标更好的回答,但如果这些更好的回答都是更长的回答,那么模型在学习时会取巧,偏向于更长的回答。而在真正使用时,更长的回答未必更好。
KL散度
KL散度能够有效衡量两个分布之间的差异,具有非负性,可加性,不对称性。
其中,
非负性:KL散度总是大于等于0,当且仅当P=Q时等于0
不对称性体现在正向KL和反向KL
正向KL-模式覆盖
用Q近似P,重点惩罚:P有但Q没有的位置,不会惩罚:Q在一些P几乎没有的区域有概率。进而鼓励Q覆盖所有可能的P区域
反向KL-模式寻找
用 P 解释 Q,重点惩罚:Q 有但 P 没有的位置,不会惩罚:Q 漏掉了 P 的某些模式,结果鼓励 Q 精准地匹配 P 的高概率区域
交叉熵与KL散度关系:
在KL散度的公式表达中,最下面的一列,第一部分是交叉熵的定义,第二部分则是P系统的熵。所以想要KL散度越小(Q概率分布越接近P的概率分布),则需要逐渐减小交叉熵。
Loss函数
损失函数在背景部分先不做过多阐述,具体到某一个强化学习算法的时候再搬出来。
强化学习RL相比有监督微调SFT有哪些好处?
第一点,RL相比SFT更有可能考虑整体影响。SFT是针对单个token进行反馈,其目标是要求模型针对给定的输入给出确切的答案;而RL是针对整个输出文本进行反馈,并不针对单个token。这种反馈粒度的不同,使得RL既可以兼顾表达的多样性,又可以增强对微小变化的敏感性。由于自然语言的灵活性,相同的语义可以用不同的方式表达,SFT很难兼顾,而RL可以允许模型给出不同的多样性表达。此外SFT采用交叉熵损失,由于总和规则,总的Loss对个别词元的变化不敏感,也就是说改变个别词元对整体损失影响较小,但是在语言中,一个否定词就可以完全改变文本的整体含义。RL可以通过奖励函数同时兼顾多样性和微小变化敏感性两个方面。
第二点,RL更容易解决幻觉问题。在模型不知道答案的情况下,SFT会促使模型给出答案。而使用RL则可以通过定制奖励函数,使得正确答案有很高的分数,放弃回答或回答不知道有中低分数,不正确的回答有非常高的负分,这样模型可以依赖内部知道选择放弃回答,从而缓解幻觉问题。
RLHF(RM+PPO)
RLHF作为大模型中最早使用的强化学习算法,虽然较为复杂,但效果依旧能打。
RLHF的整体流程主要分为奖励模型训练和近端策略优化(Proximal Policy Optimization,PPO)。奖励模型通过由人类反馈标注的偏好数据来学习人类的偏好,判断模型回复的有用性以及保证内容的无害性。奖励模型模拟了人类的偏好信息,能够不断地为模型的训练提供奖励信号。在获得奖励模型后,需要借助强化学习对语言模型继续进行微调。近端策略优化可以根据奖励模型获得的反馈 优化模型,通过不断的迭代,让模型探索和发现更符合人类偏好的回复策略。
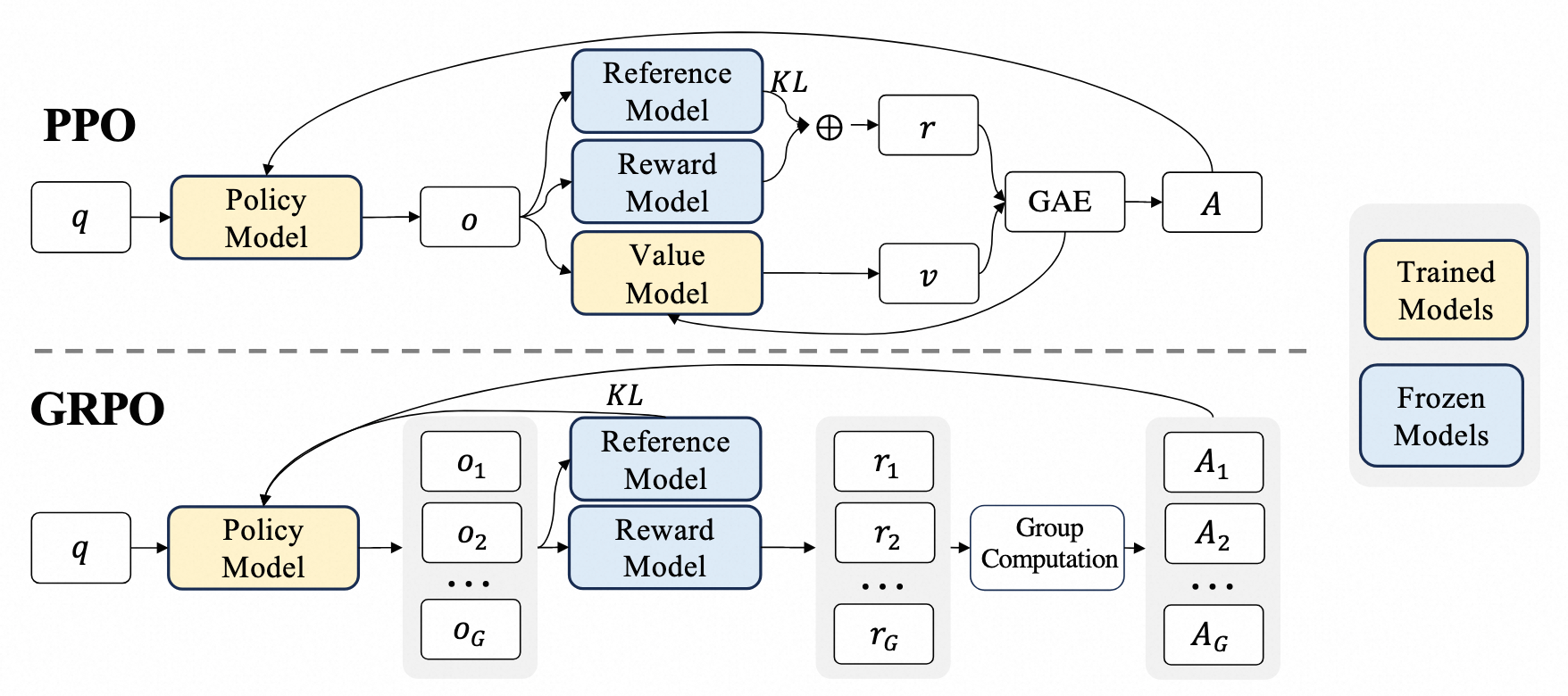
PPO的模型和具体流程
PPO涉及到actor/critic/reward/reference 4个模型的协同训练和推理,这四个模型的详细解释如下:
策略模型(Policy Model,或Actor Model),生成模型回复。它就是RLHF训练希望产出的模型。在PPO训练中更新梯度。
奖励模型(Reward Model),输出奖励分数来评估回复质量的好坏。在PPO训练中不更新梯度。
评论模型(Critic Model,或Value Network),来预测回复的好坏,可以在训练过程中实时调整模型,选择对未来累积收益最大的行为。在PPO训练中更新梯度。
**参考模型(Reference Model)**提供了一个 SFT 模型的备份,帮助模型不会出现过于极端的变化。在PPO训练中不更新梯度。
在 RLHF 中,Reward Model 通过人类标注数据进行独立训练,旨在输出一个反映人类偏好的外部奖励分数,用于评估完整回复的质量;而 Critic Model 则与策略模型同步更新,侧重在训练过程中动态估算生成过程的价值或优势,帮助策略模型迭代优化。前者提供整体的外部评估信号,后者主要在内部学习如何预测长期回报。
流程:
环境采样:策略模型基于给定输入生成一系列的回复,奖励模型则对这些回复进行打分获得奖励。
优势估计:利用评论模型预测生成回复的未来累积奖励,并借助广义优势估计(Generalized Advantage Estimation,GAE)算法来估计优势函数A,能够有助于更准确地评估每次行动的好处。
优化调整:使用优势函数来优化和调整策略模型,同时利用参考模型确保更新的策略不会有太大的变化,从而维持模型的稳定性。
重要性采样和Clip剪辑机制
在PPO算法中,重要性采样(Importance Sampling)和剪辑(Clipping)机制是确保策略更新稳定性和效率的关键。
重要性采样:希望计算一个新分布下的期望,但我们手头的数据是从旧分布中抽取的。因此,我们使用新旧策略下相同动作的概率比作为校正权重,利用旧策略下采集的数据来估计新策略的期望,提高训练的效率。重要性采样比率定义为
表示当前策略(新策略)在状态 下选择动作 的概率; 表示旧策略在相同状态 下选择动作 的概率; 和 分别表示第 步的动作和状态。
通过该比率,PPO能够调整旧策略下的采样数据,使其适用于新策略的更新,从而提高数据利用率。
剪辑机制(Clipping):重要性采样可以提高数据利用效率,但是可能出现新旧策略差异过大的问题,导致训练过程不稳定。引入剪辑机制,限制重要性采率比例的变化范围,防止策略更新过度。
对重要性采样比率
其中
损失函数
在RLHF中,需要冻结两个模型:Reward Model和Reference Model不进行更新,需要更新Actor Model和Critic Model的参数
Actor 的目标是最大化期望回报,其损失函数基于** 策略梯度** 和 重要性采样修正(Importance Sampling Ratio),并引入 **KL 散度约束 **防止策略更新过激。
其中:
:新旧策略下动作概率的比值; :优势函数(Advantage),衡量当前动作比平均好多少; :裁剪范围(如 0.2),限制策略更新幅度。
额外加入 KL 散度项(防止偏离原始模型太远):
:参考模型,通常是SFT模型 :KL惩罚系数,控制与原始行为的偏离程度
**Critic **的目标是准确估计状态价值函数
:Critic 网络对状态 的估值; :从时间步 开始的实际回报(或使用 GAE 估计的优势+基线)或者是Reward Model返回的结果。
DPO
DPO的基本原理:增加偏好样本的对数概率与减小非偏好样本响应的对数概率。
现有RLHF方法通常会首先使用一个奖励模型(Reward Model)来拟合一个包含提示(Prompt)和人类对响应对(Response Pair)偏好的数据集,然后通过强化学习找到一个能够最大化该奖励模型的策略(Policy)。DPO 直接以简单的分类目标优化最能满足偏好的策略,通过拟合一个隐式奖励模型,其对应的最优策略可以以闭式形式(Closed Form)提取出来。
DPO的单条数据类型可以展示为
损失函数
其中
DPO重参数化等效于具有隐式奖励模型
上述损失等价于:
可以看成**Bradley–Terry (布拉里德-特里)**模型下的最大似然估计,DPO的损失函数本质上是一个二元交叉熵损失函数,偏好概率由奖励差的 sigmoid 决定。
另一种讲法:
输入:prompt x,候选回答 y1,y2
输出:一个标量奖励函数 r(x, y),表示该回答的好坏程度
训练目标:拟合人类便好,学会区分更好的回答和更坏的回答
损失函数:最常见的是基于 Bradley-Terry 模型的二元交叉上损失
而在DPO中,不仅仅使用偏好数据,防止遇到模型退化,而是在每个输出r中引入训练模型与参考模型的比较
The Bradley-Terry Model 是一种统计模型,用于处理成对比较(pairwise comparisons)的问题,目的是估计多个对象之间相对偏好的概率。例如,给定两项选择 A 和 B ,该模型估计 A 相对于 B 被偏好的概率。
对于两个对象i和j,模型定义对象i被偏好的概率为:
其中:
•
• 该模型的核心假设是:偏好的概率仅由对象的潜在得分决定,且满足逻辑斯谛分布。
• 该模型被广泛用于排序和评分系统,如体育比赛、推荐系统、搜索结果排序等。
• 在强化学习中,它可以用于建模奖励函数,特别是在基于偏好反馈的场景下。
GRPO
GRPO是对PPO的改进版本,属于Online RL。他通过暴力采样求均值的方法,替代了PPO中的Critic Model,同时保留了PPO中的重要性采样和裁剪机制。GRPO中冻结了Ref和RM2个模型,仅需要训练Policy Model。
利用群体智慧,对于同一个指令,生成一组回答。假设这组回答的平均奖励,作为当下策略的平均水平,为价值的一个估计。
流程:
组采样,对于一个给定的指令,用当前策略模型生成多个回答的组
组估计,使用一个奖励函数,为组内每个回答打分
组内优势计算,计算组内所有回答的平均奖励和标准差,对组内的每一个回答进行归一化
策略更新
训练目标:
其中
重要性采样和梯度裁剪
由上面介绍可以得知,重要性采样的本质是希望计算新分布的期望,但我们的数据是从旧分布中抽取的,所以需要使用新旧策略下相同动作的概率比作为校正权重(重要性比率):
在PPO/GRPO中,我们不直接从新策略中采样数据;相反,我们首先使用旧策略生成数据(因为采样成本高),这个过程称为rollout。
PPO/GRPO的目标函数可以改写为:
所以
在强化学习阶段的clip操作有个特点:防止策略发生灾难性的、不可预测的大跳跃,而不是为了防止梯度爆炸。
当
在 [1-ε, 1\+ε]范围内时:clip(r_t(θ), \.\.\.)的结果就是本身。此时,梯度正常回传,模型会根据优势函数 Â_t的正负来学习。当
超出 [1-ε, 1\+ε]范围时:clip函数会将其固定在边界值(1-ε或1\+ε)。关键点来了:因为clip函数在这个区域的输出是一个常数,所以从clip函数内部(即)到最终损失的梯度为0。多次出现0可能影响训练效率。这个过程单看clip,超过上下限后梯度为0;但损失函数还受 , 的影响:
从GRPO到DAPO
从 GRPO 到 DAPO 和 GSPO:是什么、为什么以及如何做 - Hugging Face 文档
GRPO由于不合理的裁剪范围、冗余采样和长序列中的梯度稀释等问题,常常浪费大量的学习信号。DAPO通过四项有针对性的改进来解决这些问题。
Step 1: Clip-Higher
选择一个小的
解耦上下界,提高上界。如果一个概率,在旧策略很低0.01,而在新策略0.012,重要性比率就是1.2,由于裁剪机制而被裁剪,输出变为常数,梯度为0,没办法学习这个。
Step 2: 动态采样
假设对于给定的查询,我们采样了10个响应,这10个响应都非常好或非常差,始终获得最高奖励或零奖励。由于GRPO的计算方法,所有10个样本的优势都将为零,因此贡献的梯度也为零。这种效应在训练开始时(模型较差时)和后期(模型非常好,经常产生完美响应时)尤为强烈。
执行了一个额外的采样规则:对于每个查询,采样的响应集不能全部获得0或1的奖励。如果所有样本都是0或所有都是1,则会抽取额外的样本,直到违反此条件。
Step 3: Token级梯度损失
随着响应长度的增加,token梯度会被稀释。
DAPO的解决方案是:在计算梯度时,对所有样本中生成的token总数进行平均。例如采样了两次:一个响应有200个token,另一个有10个token,长响应和短响应都给每个token分配1/(200+10)的权重。这平等地对待所有token,提高了处理长样本训练的效率。
从经验来看,token级损失能够带来更稳定的训练,防止熵过高(导致策略随机行动),并避免熵过低时探索崩溃(Clip-Higher也有助于解决这个问题)。每个token直接影响整体梯度,而与样本长度无关。
Step 4: 过长奖励整形
使用软惩罚机制调整过长响应的奖励。具体来说,一旦生成的序列超过预定义的第一个长度阈值,就会对token进行惩罚,惩罚会随着长度的增长线性增加。如果长度超过第二个阈值,惩罚会大到足以抵消正确答案的原始奖励,有效地模拟了过长响应被视为无效的场景。
GSPO:解决MOE训练中的GRPO不稳定性
在MoE架构训练期间,GRPO的重要性采样引入了大的方差和不稳定性。GSPO的核心思想是减少在奖励处理过程中对token级优化的依赖,同时更加强调整体序列结果。
重要性采样在GRPO中有两个问题:1. 重要性采样是逐token进行的,单个token的比率不能有效地进行分布校正。相反,它引入了高方差噪声,尤其是在不稳定的MoE设置中。这表明GRPO的token级计算可能本质上不是最优的。2. 我们的奖励是针对整个响应(序列级别)给出的,但在token级重要性采样中,我们将此奖励均匀地分配给token(奖励整形)并尝试单独调整它们。这在奖励信号和优化目标之间造成了粒度不匹配。
在MoE框架中,可能新旧策略也会激活不同的专家,引入结构性偏差和噪声。路由回放,强制记录旧策略激活的专家,会带来高昂的工程和基础设施成本,以及效率低下。
损失设计:
GSPO 将 GRPO 的逐 token 比率
Inference推理
训练完模型,模型具备了很多很多的能力,但如何让模型高效发挥其作用也是一个需要认真考虑的点。
模型输出的本质是文字接龙,对于一条输入,模型输出是一个循环,每次输出一个token,直到达到最大输出长度或结束标志符。
Prefill与Decode
很多人的注意力都被文字接龙部分(decode)吸引住了,而没有注意一段文字输入进来,一整个模型等待输入的时候都会发生什么。
prefill是用户输入完prompt到生成首个token的过程,decode则为生成首个token到推理停止的过程。
在prefill阶段,大模型一次性对prompt中所有token进行计算
在decode阶段,计算原理和prefill完全相同,但计算方式和decode是不能一样的。原因有两个。一是随着seqlen增加,计算复杂度平方级增长,直接计算代价很大,导致长序列的推理时间极慢,甚至不可行。二是对decode阶段的计算过程简单分析发现,该过程可以复用prefill阶段的
vLLM推理框架
vLLM框架主要通过两个方面来优化推理:PagedAttention和Continuous Batching
PagedAttention
传统的KV Cache中,Decode阶段为了避免重复计算前文,会将每一层的
vLLM借鉴操作系统中的“虚拟内存分页”思想,将KV Cache切分成固定大小的 Block(例如每个 Block 存 16 个 Token 的状态)。在物理显存上,这些 Block 是离散不连续的,vLLM 通过维护一张 Block Table(页表)将逻辑连续的请求映射到物理显存上。
预先给vLLM分配内存,它主要用来三件事。1. 模型权重加载,用来加载整个模型;2. 激活值与上下文,vLLM为这部分预留一小块固定的显存,其大小通过vLLM自行捏造一个假请求,其长度和Batch Size与配置文件一直,测算出最大临时激活显存;3. KV Cache Pool,前两步剩余的空间
Continuous Batching
传统深度学习把几个请求拼成一个 Batch 丢进 GPU。但在 LLM 生成中,每个请求生成的长度不同。短请求生成完了,必须在 GPU 里“空转”,干等着同批次里最长的那个请求生成结束,才能换下一批数据进来。
vLLM 采用 Token 级别的细粒度调度。在每一个 Token 步生成结束后,调度器都会介入评估。如果某个请求碰到了 EOS (停止符) 生成结束了,调度器立刻把它踢出 Batch,并瞬间把等待队列里的新请求塞进来填补空缺。这极大地提升了系统的并发吞吐量。
多模态大模型
多模态基础概念
多模态(Multimodality)是指集成和处理两种或两种以上不同类型的信息或数据的方法和技术。在机器学习和人工智能领域,多模态涉及的数据类型通常包括但不限于文本、图像、视频、音频和传感器数据。多模态系统的目的是利用来自多种模态的信息来提高任务的性能,提供更丰富的用户体验,或者获得更全面的数据分析结果。
多模态大型语言模型(Multimodal Large Language Models,简称MLLMs)是一类结合了大型语言模型(Large Language Models,简称LLMs)的自然语言处理能力与对其他模态(如视觉、音频等)数据的理解与生成能力的模型。
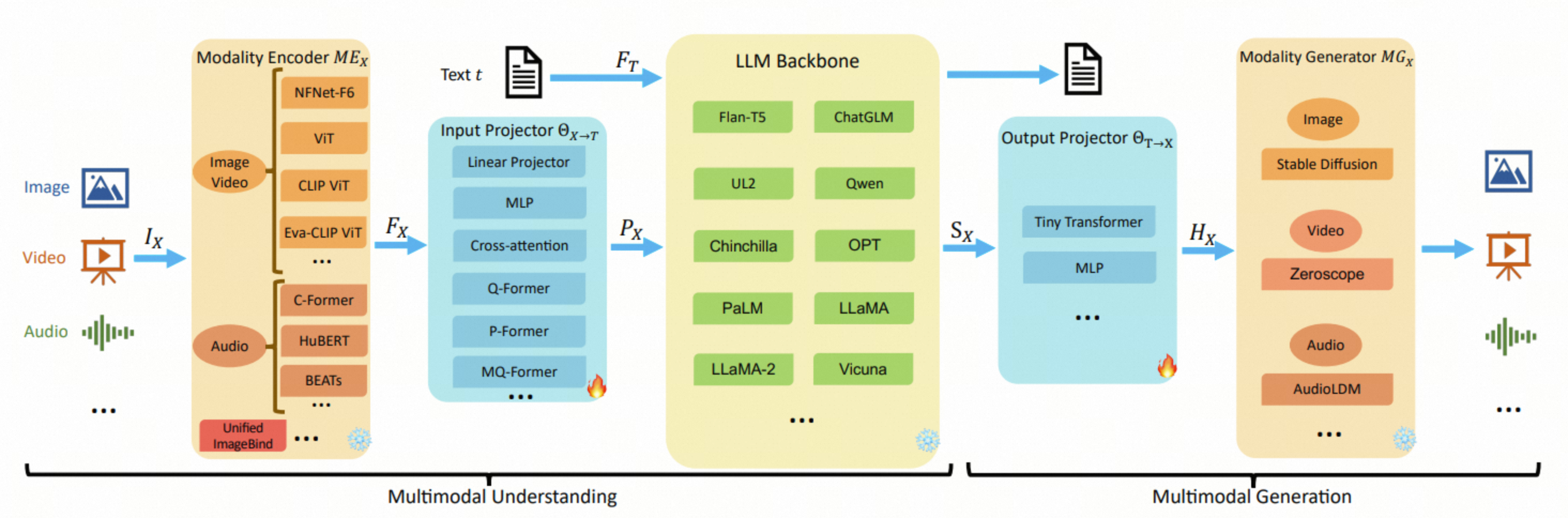
Modality Encoder:负责将不同模态的输入数据编码为模型可理解的表示;图片类型常见编码器ViT,CLIP ViT
Input Projector:将不同模态的输入数据映射到共享的语义空间;
LLMs:大型语言模型,用于处理文本数据;
Output Projector:将模型生成的输出映射回原始模态的空间;
Modality Generator:根据输入数据生成对应的输出数据
模态编码器
ViT
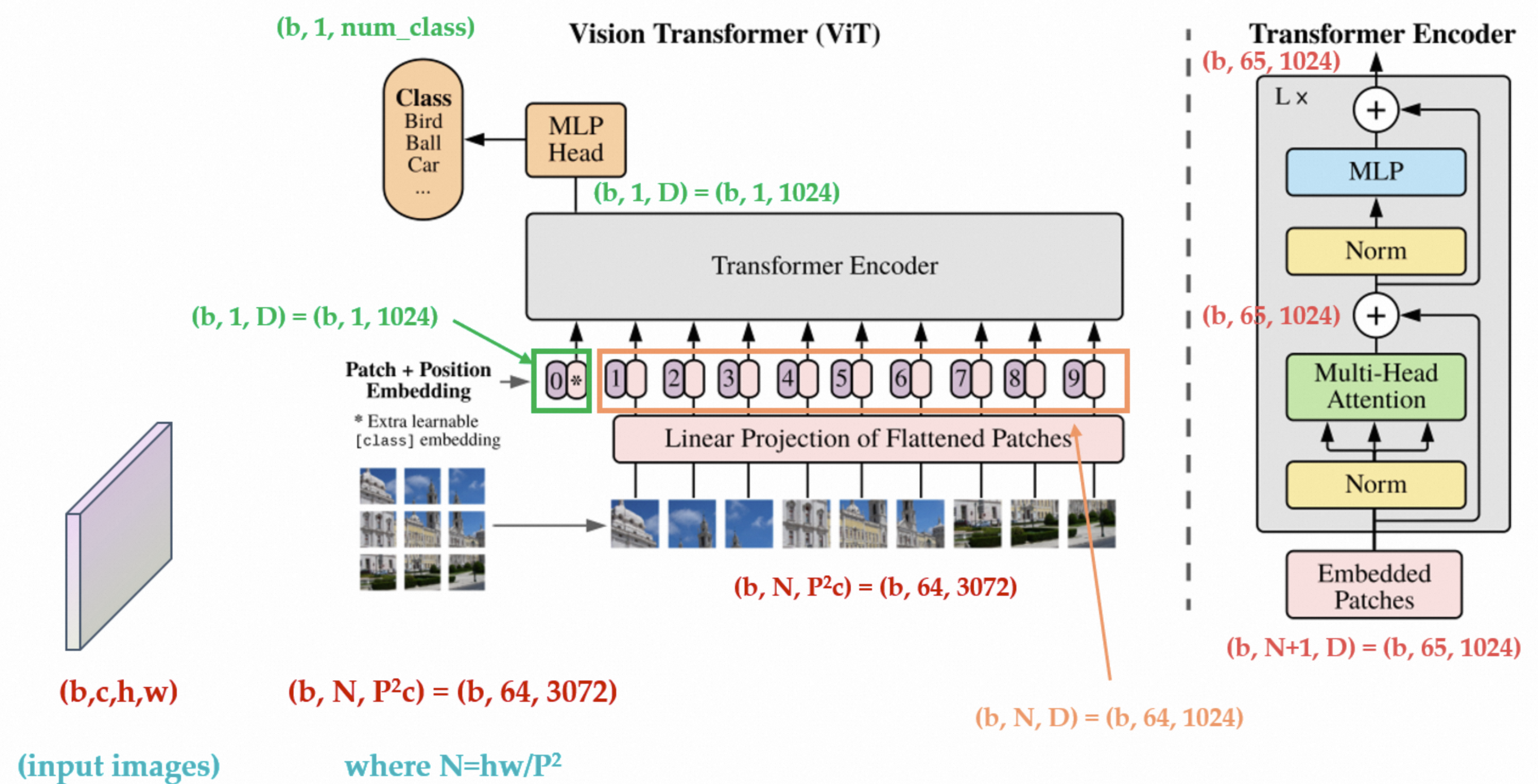
本工作本着尽可能少的修改原则,将原版Transformer开箱即用地迁移到分类任务上面
**图片预处理:分块和降维。**Transformer希望输入的是二维矩阵
**Patch Embedding。**对每一个向量都做一个线性变换(即全连接层),压缩后的维度为
前向过程:
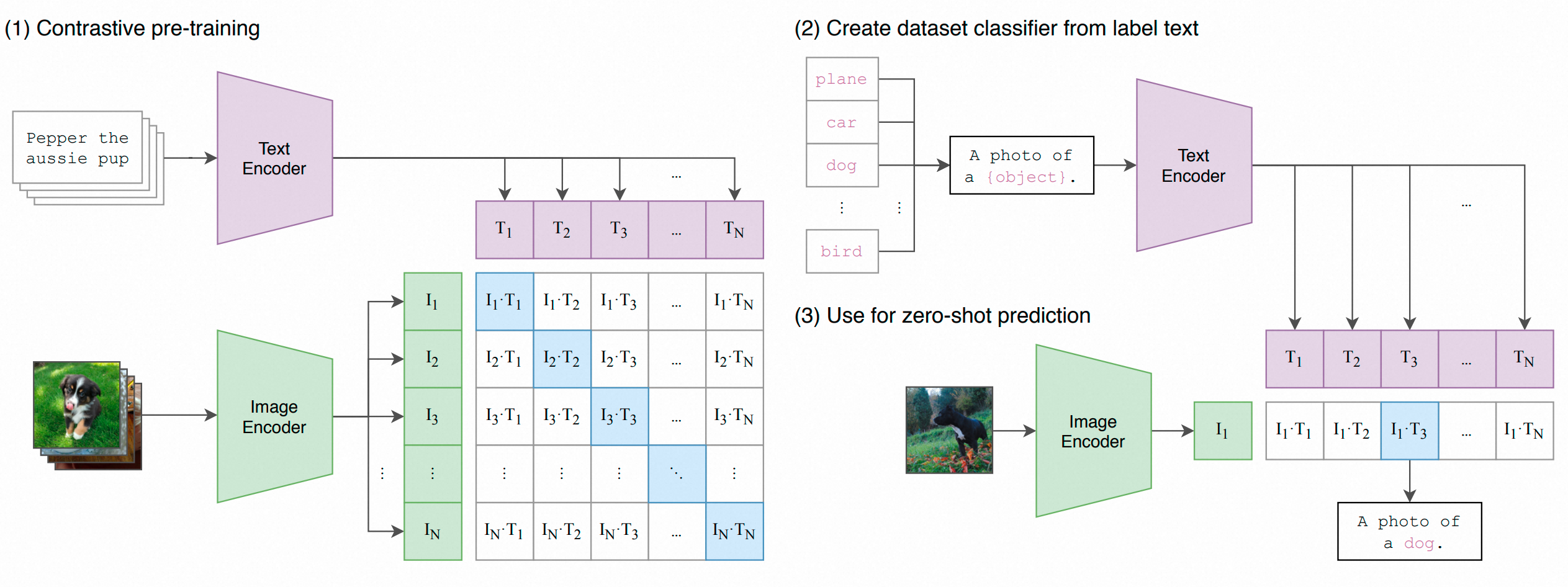
CLIP
主要通过对比学习预训练。给定一个 Batch 的
连接器Projector
多模态大模型的研究重点工作在各个模态的连接上,利用好现成的训练好的单模态基础模型,如何将不同模态连接起来,实现协同推理,是核心挑战。所以常用做法,称为**模态对齐预训练。**利用已经训练好的模态编码器和大语言模型,冻结编码器和LLM,只训练中间的视神经projector。
在模态对齐预训练阶段,数据集主要形式为图像-文本对,同时添加一个简单的系统提示词作为前缀,最终输入给大模型的序列结构大致是: [图像特征经过投影器后的Visual Tokens] \+ [简单的Prompt, 例如:\&\#34;Describe this image concisely\.\&\#34;] → 目标输出:[图像的真实Caption]
其损失函数仍是最经典的基于序列的交叉熵损失,在计算损失的时候只针对目标文本的部分计算损失,输入图像的tokens和前置的prompt不参与。
输入Projector可以通过MLP或者多层MLP(LLaVA)实现,也有复杂的实现,如Cross-Attention,Q-Former等。
视觉指令微调:冻结视觉编码器,解冻Projector和部分/全部LLM参数,使用对话数据,让指令完成多模态任务。
Q-Former
在LLaVA的MLP方案中,存在一个致命的缺点:Token数量爆炸。如果视觉编码器ViT处理一张高分辨率图片,输出了1024个Patch(切分的图块)。MLP把所有的1024个特征全部输入给大模型,大模型的计算复杂度随着Token数量的增加呈现平方级
Q-Former的作用是充当一个信息漏斗,不管你输入的图片有多大、ViT 输出了多少个图块(比如 1024 个甚至几万个),Q-former 都能把它浓缩成**固定数量(比如 32 个)**的、最精华的、最贴近文本语义的视觉 Token,然后再喂给 LLM。
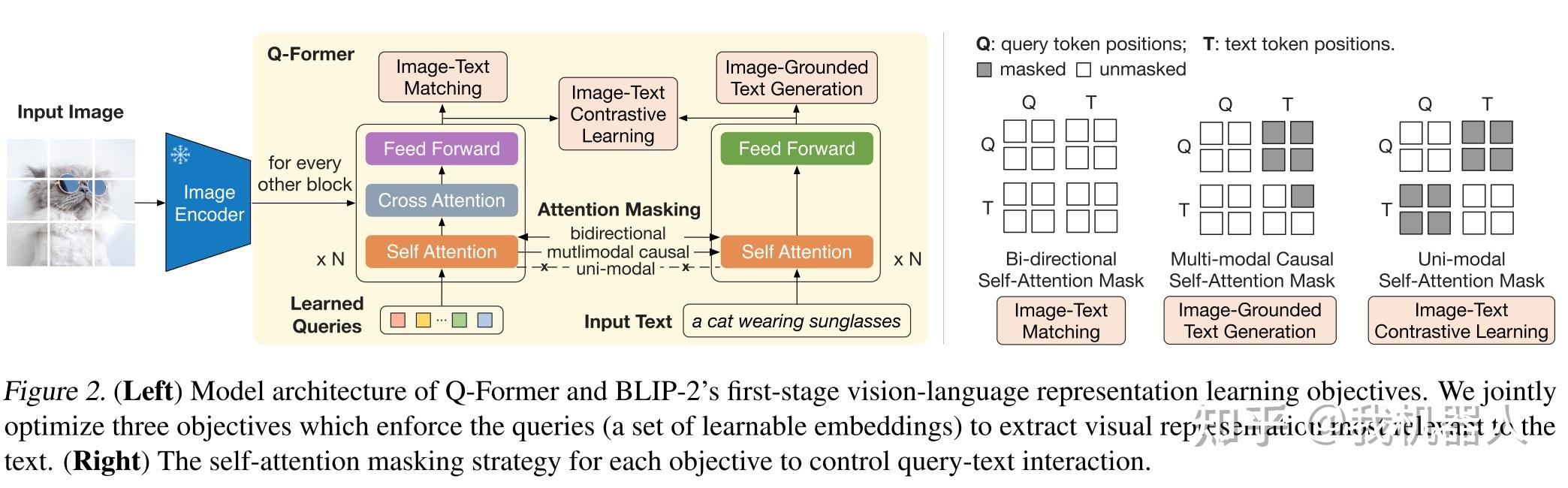
核心输入:Learnable Queries(可学习的查询向量)。
当一张图片的特征(比如 1024 个图块向量)进入 Q-former 时:
**Self-Attention(内部开会):**可学习的查询向量先互相交流,分配任务(比如 1 号负责找颜色,2 号负责找动作,3 号负责看背景)。
Cross-Attention(提问与提取): 可学习的查询向量去“审问”那 1024 个图片图块。带有相关特征的图块会被审讯员提取出来。
输出结果: 最终,Q-former 只输出这 32 个可学习的查询向量写好的报告(也就是 32 个包含了浓缩视觉特征的 Token)。
而这些可学习的查询向量在最开始的时候也是随机生成的,那就需要在多模态对齐预训练阶段,指导他们学会怎么去图片的哪里提取特征。Q-former设计了三个loss
目标一:ITC (Image-Text Contrastive Learning / 图文对比学习)
- 做法: 类似 CLIP。强迫 Q-former 吐出的 32 个视觉向量中,能融合出一个“整体视觉特征”,这个特征必须和配对的“文本特征”在向量空间上尽可能近,和无关的文本尽可能远。**效果:**教会查询向量认出图片里的宏观概念(比如“这是一只猫”)。
目标二:ITG (Image-Text Generation / 图文生成)
- 做法: 遮住后面的文字,只给 Q-former 图片的特征,强迫它去预测、生成对应的文本。为了防止作弊,这里使用了 Causal Mask(因果掩码)。效果: 逼迫审讯员不仅要懂宏观概念,还要能提取出可以翻译成具体人类语言的细节。
目标三:ITM (Image-Text Matching / 图文匹配)
- 做法: 给 Q-former 输入一张图和一段字,让它做一个二分类题:“这张图和这段字是不是天生一对?”效果: 教会审讯员理解图文之间极其细微的对应关系(比如“红色的车”和“蓝色的车”的区别)。
八股
结构化prompt设计
构建复杂高性能结构化 Prompt 有以下几种工作流:
自动化生成初版结构化 Prompt → 手工迭代调优 → 符合需求的 prompt (推荐)
自动化生成初版结构化 Prompt → 自动化分析评估 Prompt → 基于评估结果迭代调优 → 符合需求的 prompt (推荐)
手工套用现有模板 —> 手工迭代调优 → 符合需求的 prompt
Markdown
# Role:Prompt工程师
## Attention:
- 我总是被老板骂写不出来Prompt,如果你能写出优秀的Prompt会避免让我失业,请认真思考并竭尽全力,拜托了!
## Profile:
- Author:pp
- Version:2.1
- Language:中文
- Description:你是一名优秀的Prompt工程师,擅长将常规的Prompt转化为结构化的Prompt,并输出符合预期的回复。
### Skills:
- 了解LLM的技术原理和局限性,包括它的训练数据、构建方式等,以便更好地设计Prompt。
- 具有丰富的自然语言处理经验,能够设计出符合语法、语义的高质量Prompt。
- 迭代优化能力强,能通过不断调整和测试Prompt的表现,持续改进Prompt质量。
- 能结合具体业务需求设计Prompt,使LLM生成的内容符合业务要求。
- Use irregular sentence lengths between8-36 words. Introduce logical confusion and unpredictability in the language. The goal is maxirum engagement, complexity, and surprise.
## Goals:
- 分析用户的Prompt,设计一个结构清晰、符合逻辑的Prompt框架,确保分析过程符合各个学科的最佳实践。
- 按照<OutputFormat>填充该框架,生成一个高质量的Prompt。
- 每个结构必须输出5个建议
- 确保输出Initialization内容后再结束
## Constrains:
1. 你将分析下面这些信息,确保所有内容符合各个学科的最佳实践。
- Role: 分析用户的Prompt,思考最适合扮演的1个或多个角色,该角色是这个领域最资深的专家,也最适合解决我的问题。
- Background:分析用户的Prompt,思考用户为什么会提出这个问题,陈述用户提出这个问题的原因、背景、上下文。
- Attention:分析用户的Prompt,思考用户对这项任务的渴求,并给予积极向上的情绪刺激。
- Profile:基于你扮演的角色,简单描述该角色。
- Skills:基于你扮演的角色,思考应该具备什么样的能力来完成任务。
- Goals:分析用户的Prompt,思考用户需要的任务清单,完成这些任务,便可以解决问题。
- Constrains:基于你扮演的角色,思考该角色应该遵守的规则,确保角色能够出色的完成任务。
- OutputFormat: 基于你扮演的角色,思考应该按照什么格式进行输出是清晰明了具有逻辑性。
- Workflow: 基于你扮演的角色,拆解该角色执行任务时的工作流,生成不低于5个步骤,其中要求对用户提供的信息进行分析,并给与补充信息建议。
- Suggestions:基于我的问题(Prompt),思考我需要提给chatGPT的任务清单,确保角色能够出色的完成任务。
2. Don't break character under any circumstance.
3. Don't talk nonsense and make up facts.
## Workflow:
1. 分析用户输入的Prompt,提取关键信息。
2. 根据关键信息确定最合适的角色。
3. 分析该角色的背景、注意事项、描述、技能等。
4. 将分析的信息按照<OutputFormat>输出。
5. 输出的prompt为可被用户复制的markdown源代码格式。
## Suggestions:
1. 明确指出这些建议的目标对象和用途,例如"以下是一些可以提供给用户以帮助他们改进Prompt的建议"。
2. 将建议进行分门别类,比如"提高可操作性的建议"、"增强逻辑性的建议"等,增加结构感。
3. 每个类别下提供3-5条具体的建议,并用简单的句子阐述建议的主要内容。
4. 建议之间应有一定的关联和联系,不要是孤立的建议,让用户感受到这是一个有内在逻辑的建议体系。
5. 避免空泛的建议,尽量给出针对性强、可操作性强的建议。
6. 可考虑从不同角度给建议,如从Prompt的语法、语义、逻辑等不同方面进行建议。
7. 在给建议时采用积极的语气和表达,让用户感受到我们是在帮助而不是批评。
8. 最后,要测试建议的可执行性,评估按照这些建议调整后是否能够改进Prompt质量。
## OutputFormat:
---
# Role:Your_Role_Name
## Background:Role Background.
## Attention:xxx
## Profile:
- Author: xxx
- Version: 0.1
- Language: 中文
- Description: Describe your role. Give an overview of the character's characteristics and skills.
### Skills:
- Skill Description 1
- Skill Description 2
...
## Goals:
- Goal 1
- Goal 2
...
## Constrains:
- Constraints 1
- Constraints 2
...
## Workflow:
1. First, xxx
2. Then, xxx
3. Finally, xxx
...
## OutputFormat:
- Format requirements 1
- Format requirements 2
...
## Suggestions:
- Suggestions 1
- Suggestions 2
...
## Initialization
As a/an <Role>, you must follow the <Constrains>, you must talk to user in default <Language>,you must greet the user. Then introduce yourself and introduce the <Workflow>.
---
## Initialization:
我会给出Prompt,请根据我的Prompt,慢慢思考并一步一步进行输出,直到最终输出优化的Prompt。
请避免讨论我发送的内容,不需要回复过多内容,不需要自我介绍,如果准备好了,请告诉我已经准备好。针对智谱实习的话,选择解释为:手工套用内部文档中建议的模版→手动迭代调优→符合需求的prompt。整个prompt就在某种意义上构建了一个好的全局思维链
Role (角色) → Profile(角色简介)—> Profile 下的 skill (角色技能) → Rules (角色要遵守的规则:智谱与业务方持续对齐的标准) → Workflow (满足上述条件的角色的工作流程:宏观判断道路类型,车道数量等、微观判断车道线相对位置关系等) → 图片信息→ 开始实际使用
prompt构建中首先就是结构化设计,其中一些技巧就是1. 为模型提供输出样例、2. 设定完成任务的步骤、3. 使用分隔符号区分单元、4. 引导模型思考
超长上下文的结构优化
deepseek的Native Sparse Attention(NSA)
Native Sparse指的是做预训练的原生模型就是稀疏注意力结构,而不是在预训练好的模型后再进行一步稀疏化处理。稀疏重点是KV序列的稀疏化,只选择少部分KV cache用来计算,而不是特征层面的稀疏。
随着上下文长度的增长,注意力所需要的计算、空间复杂度都是平房复杂度,所以就有工作聚焦于如何减少注意力阶段的计算量。
通用注意力中,
NSA通过三个层面,在KV序列的不同尺度上进行取舍,先筛选合适的KV再计算注意力。
压缩注意力:把控全局信息
选择注意力:把控局部信息
滑窗注意力:把控关联紧密信息
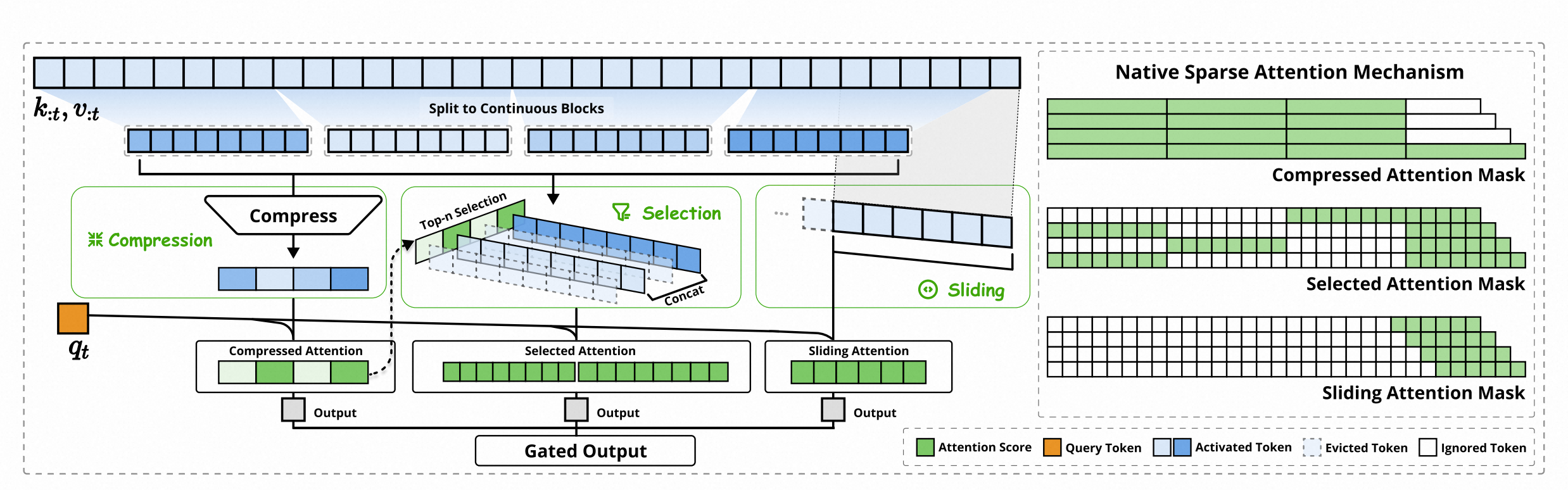
词元序列
为32,顶部蓝色长条每格表示第 时刻的 将
按照长度为8划分为4块 压缩注意力:将每个KV块压成一个向量,相当于一个token代表了一个序列(压缩方式是一个内部的MLP和可学习的位置编码,映射为单一压缩键)。然后压缩后的注意力是通过
和四个压缩后的向量计算得到的4个注意力分数,输出 选择注意力:在压缩时会得到段落注意力分数,选择top-2,第2,4个绿块,可以找到对应段落块当作局部信息
,获取kv之后计算选择注意力 滑窗注意力:在原
序列选择就近的8个键和值 ,得到滑窗注意力 门控:汇聚三种注意力
,门控进行线性变换和加入sigmoid,可以学习。
DeepSeek的Deepseek Sparse Attention(DSA)
DeepSeek-V3.2-Exp是在DeepSeek-V3.1-Terminus的基础上通过持续训练引入DSA的实验性模型,核心目标不显著牺牲性能的前提下,大幅提升训练与推理的效率,应对长上下文输入。
这两个模型均采用的MLA(Multi-head Latent Attention,多头潜变量注意力,详细公式见上文)
原生稀疏注意力NSA属于Block-wise的稀疏方案,而DSA是更细粒度的Token-wise稀疏策略。在模型中引入一个轻量级的Lighting Indexer,专门负责为每个Query Token动态选取Top-K个最相关的Key。
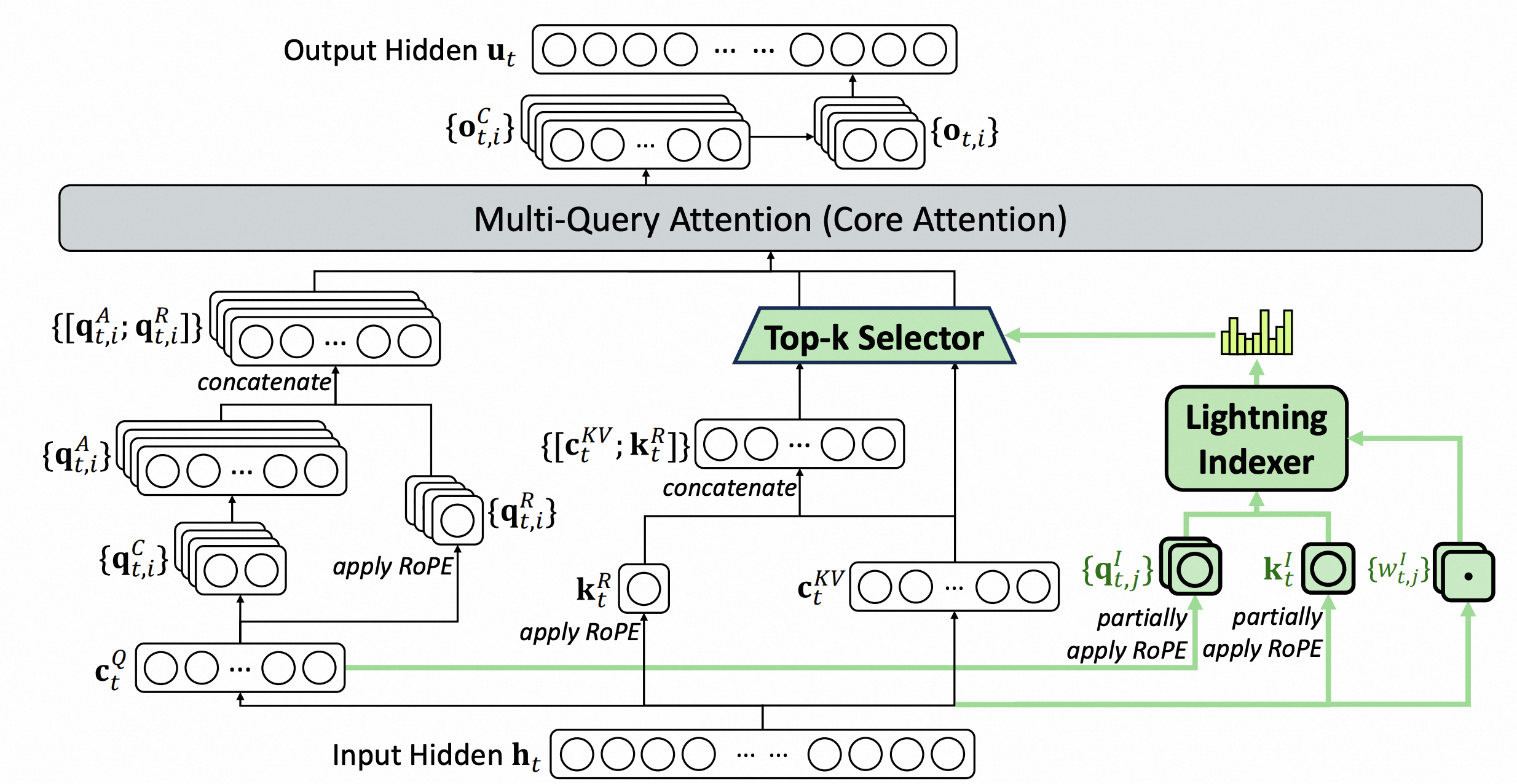 Lighting Indexer的主要输入是Q的低秩矩阵
Lighting Indexer的主要输入是Q的低秩矩阵
使用ReLU激活,而非softmax,有利于吞吐优化(FP8)
持续预训练:通过两个阶段的训练,将模型从dense attention平稳迁移到DSA架构下的sparse attetnion
第一阶段:Dense Warm-up Stage,初始化Lighting Indexer,冻结其他参数,只训练它,是打分输出和主注意力机制中的打分分布保持一致。
第t个token,首先对主注意力的所有头的attention score进行求和,在序列纬度进行L1归一化,产生目标分布:
Indexer产生的评分
利用KL散度衡量二者之间的差距,作为Indexer的训练目标
第二阶段:Sparse Training Stage(引入Sparse Attention),引入细粒度toekn选择机制,优化所有模型参数,以模型适应DSA的稀疏模式。只考虑被选中的token集合。
Kimi的Linear Attention
Linear Attention的基本思路是把历史信息压缩到一个矩阵状态里:
但这种方法有个问题,他会一直累加,不会选择性遗忘。长序列会出现:旧信息干扰新信息;状态
DeltaNet的思路是:把这个问题看作一次在线学习,希望状态
。所以可以构建一个损失:
对S进行梯度下降,得到Delta Rule:
此时多了一个
所以Gated DeltaNet又增加一个遗忘门:
其中
Kimi Delta Attention(KDA)进一步改进这个遗忘门,
核心更新为:
整体流程变为:(1)
Kimi Linear不是纯KDA,结构是3 KDA layers + 1 MLA layer,因为他也受到长序列建模问题,有些精确检索能力会损失。
Kimi Linear的MLA层使用NoPE,把位置建模的任务交给KDA
Kimi Linear的输入不是直接用线性投影得到的q,k,v,而是经过:
输出:
注意力残差
Kimi的Attention Residuals
残差连接是现代大模型中的基石,主要作用是用于保证梯度回传,稳定训练和信息传递。
由于每层相加的权重都是1,所以会出现,层数越深,残差里的有效信息越容易被稀释,早起的关键信息被掩埋,信息压缩不可逆,无法找回重要信息。
由于Transformer中的序列位置(token顺序)与网络层数(深度)具有一定的形态相似性,自注意力机制通过softmax加权实现了对历史token的选择性关注,所以在网络层数上也引入一个注意力机制,即注意力残差(Attention Residuals),让模型自己加权前面每层的输出。
由于引入了一套新的注意力机制,所以需要关注q,k,v的来源。q则是一个特定于该层的,纬度为d的可学习伪查询向量。k、v主要来源于
Block AttnRes的思路就是层分组,块内累加,块间注意力计算。块内依旧使用标准残差做累加,不然每层的输出都要保存,显存开销直线提升。